佛教圖書館館訊 第十四期 87年 6月
從實務經驗談電子佛典初步工程之演進
中華電子佛典協會 吳寶原
maha@tpts1.seed.net.tw
【摘要】:本文針對大藏經電子化的基礎工作——輸入、校對,從技術層面的實務經驗中,略述傳統作業模式的演進過程,期盼未來能做出高度精確的電子藏經。
關鍵詞:漢文大藏經;電子佛典;辨識;檔案比對;看圖校對
一、前言
在數位資訊時代,相信重視資訊應用的人皆已受用到電子媒介所帶來的便利。除了網路上呈現的諸多電子佛典外,尚有佛光山的「佛光大辭典」、資訊功德會的「金剛經專集」以及新近出版的「印順法師佛學著作集」等光碟產品,都帶給我們前所未有的震撼與驚喜。其實,我們更深的期盼是——早日將全套漢文大藏經予以電子化。
任誰都會覺得,這期盼是一個龐大工程,包括輸入、校對、缺字、校勘、標記、檢索、使用介面等,每一環節所面對的都是數量巨大、變化多端的材料,皆非三言兩語所能道盡,因此本文僅先針對此項大工程中的前兩項步驟——輸入、校對,略述技術層面的演進過程,不光談理論架構,而是就實務經驗來分享交流,從傳統作業模式進而模擬出未來作業模式的可能演進。
二、從一封信談起
筆者目前任職於中華電子佛典協會(CBETA)。本協會由恆清法師促成,獲北美印順導師基金會經援,並蒙中華佛研所全力贊助,於今年(1998 )二月中旬在台北正式成立。四月五日,筆者對協會內部發表底下一函,以為同事間相互砥礪,陳述個人對於整理電子佛典所持態度:
電子佛典這條路,並沒有人留下一套作業模式可循,而是我們正在創造這套作業模式,所以整個可能的流程步驟及預期成果有著不可測的因素。
如要否定上面這個「創造」說,我相信電子佛典也是可以做。很簡單嘛!花小錢到大陸打字,每月固定三冊;台灣這邊,請工讀生或義工來校對,每月固定三冊校一次,共做四校;至於缺字,弄個造字檔就行了;最後,找一兩個發心的程式高手來設計檢索程式及使用介面。這樣就成了,看來一切都在掌控之中,既經濟又有效率,應該不出三年就可以完成大正藏前55冊。
上面這段描述,相信是大多數人對「電子佛典」的印象,只要這樣一講,保證對方一聽就懂。可是,事情如果可以這麼簡單,為什麼一直沒有人全面完成它呢?難道以台灣佛教界的力量,只消幾根大柱子的錢,加上動員信眾,如此處理早就弄出來了,還輪得到我們在此操刀嗎?(莫提什麼版權問題,除大正藏外,還有那麼多套沒版權的珍貴藏經值得進行啊!)
回想十年前(1988年),筆者剛退伍,到某家出版社從事藏經編輯工作。月領台幣8000多元,每天標點20頁大正藏,工作效率之高令人咋舌。但對自己的工作成績一直感到很慚愧,因為在一些不明之處,根本沒時間去翻查字典、辭典,只能依著作業經驗去勉強處理。在公司的立場,我可能是一個好用的佛經標點機器;但在自身的感受上,這樣的職業生涯是很無趣的。
聊這往事,主要在申明個人對品質的重視。所謂的「產品」,不是說有東西出來就好;可能的話,在條件許可下,對於品質應該全力以赴。又,所謂的「條件」,是可以爭取的,尤其我們在這草創之初,不要輕易的把自己綁手綁腳了。
最近這兩年多來,自參與網路BudaTech(佛典電子化專區)討論,深深感受到電子佛典技術層面的重要。若沒有這些技術討論,今天在OCR(中文印刷字體光學字元辨識系統)、檔案比對、缺字處理、檢索應用等各方面很難有這麼多實用技術及程式。
要成就一個實用技術或程式,不是那麼容易,比如說檔案比對等,必先要有人大力提出構想(來自DOS FC指令),然後試作雛型(實際以兩份經文電子檔比對),比較現有程式(和中研院資訊所的文件比較程式有何不同),進而著手設計程式(FGFC程式)、程式測試(除錯以及研究改進之處)、修改程式(越改越好用),一直到現在改了六次還在改。
以目前協會的狀況,不是說我們的程式人員功力如何了得,而是他們能夠了解實際作業需求,所以配合度高,可以寫出切中要害的東西。另外,我們的測試員也很用心,不停地進行實務操作,不斷地發現關鍵問題,讓程式人員越寫越起勁。
如此,透過程式設計的協助,人工鍵入改成OCR,傳統校對變成檔案比對。不但能質量兼顧,且能讓工作人員做起事來輕鬆愉快。但是,這些程式尚未止於至善,要如何使其趨近於善?這還有待大家在作業前置期一起再加把勁的。
三、輸入方面的重大改進——OCR
自從有中文OCR以來,已經有不少個人或單位嘗試以它來大量產生電子佛典。因為它實在很快,以現在的普及電腦,一秒鐘要產生20字以上是沒問題的。而傳統的打字速度呢?一秒鐘一個字算不錯了。
筆者在六年前,當擁有掃瞄器及鼎展中文OCR時,也曾懷著雄心壯志要開始掃瞄及辨識大正藏。可是,實際做下去,效果比預期差很多。問題的主要關鍵有二:
1. 辨識軟體之整體辨識率及版面分割能力有待提昇。
2. 大正藏原文字旁常有日本讀音符號,常會大大干擾文字辨識。
問題的解決
時至今日,辨識軟體的功能不斷增益,上述第一點已有較好的改進。以丹青中文OCR 2.0專業版而言,在「良好的操作」下,對於大正藏已有92-93% 的正確辨識率。
所謂「良好的操作」是指:
1. 掃瞄時設定最佳的黑白臨界值,使掃瞄出來的圖檔不致過濃或過淡。
2. 手動分割辨識區域,將欲辨識欄一個一個分割出來。
3. 善用其「學習字庫」功能,將辨識不易的圖形強迫系統學習。
至於「大正藏原文字旁常有日本讀音符號」,此一問題在去年八月經與幾位網友討論,終於由周海文先生寫了一支專門去除圖檔特殊符號的fgmvdot程式,除了可以針對大正藏,也可以用來處理「卍續藏」及「佛教大藏經」。有了這支程式,大正藏的掃瞄辨識正確率可以提昇至95%。以上所言,其實際測試報告撰寫於去年十月,摘要如下:
本測試以新文豐版大正藏第九冊第29頁上、中、下三欄為素材,扣除圈點等符號及電腦缺字,共有1161個中文字。
經上回測試,350dpi-23無疑是利用fgmvdot來去除雜點的最佳組合。那麼到底fgmvdot對於整體辨識效率的增益有多少?是否程式去點可以媲美手工去點?這是本次測試的主要目的。
底下以四份文件來測試:
1. [未去雜點]:未去除任何雜點加以辨識所得的文字,每一錯誤處標示一個X。
2. [程式去點]:以350dpi-23的條件利用程式去點後辨識所得的文字,每一錯誤處標
示一個Y。
3. [手工去點]:以手工去點後加以辨識所得的文字,每一錯誤處標示一個Z。
4. [正確文字]:經校對正確的本頁文字。
掃瞄圖在未去雜點時,因為雜點的影響,辨識軟體常將雜點辨識成「1」、「.」、「.」、「i 」等半形及全形符號,這些符號有一定規則,可以在事後以搜尋取代方式快速去除,所以不當做是錯誤來計算;但若因雜點影響,而造成辨識軟體辨識出錯誤的字,或增字,尤其是增出「一」字,這些都列入計算錯誤的範圍。
結果:
X[未去雜點]=166→正確辨識率=(1161-166)/1161=85.70%
Y[程式去點]=95→正確辨識率=(1161-95)/1161=91.82%
Z[手工去點]=92→正確辨識率=(1161-92)/1161=92.08%
Y的數值與Z相當接近,表示程式去點的作用幾乎等於手工去點。由此看來,fgmvdot的成績非凡!
在這個測試裡,仍然是採用繁體6142字集、無學習字庫,以程式去點後的正確辨識率為91.82%。這樣的效果,如果能再好好利用學習字庫,相信要突破95%的正確辨識率不足為難。
PS. 據資功會實測,回報說有96-98%的正確率。
更厲害的作法之一
儘管OCR可以產生95%正確率的經文檔,也就是說一百個字裡可能錯五個字,這還是很粗糙的,所以我們還得利用OCR軟體所提供的線上校對功能來進行逐字校對。可是,這個線上校對也是很辛苦的,大正藏一頁三欄,總得花個半小時才能校對完畢。
後來,網友楊忠權先生寫了一支PlusOCR程式(見附圖一),用以擴增OCR軟體兩項功能:
1. 線上校對時,字串圖形緊隨著校對文字跑。
2. 線上校對前可以把OCR常犯辨識錯誤先行取代為正確字串。
【圖一】
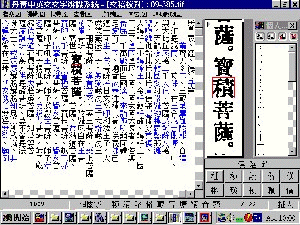
這一招確實為我們省下不少力氣,並提高OCR經文檔的正確度。
更厲害的作法之二
目前我們嘗試一種較為大膽的作法,將OCR初步辨識過的文字檔,不再進行線上校對,直接存檔出去。然後,利用所建立的<OCR常犯錯誤字串取代表>,以OPEN 98所提供的字串取代Convert程式跑過一遍。
之所以敢這麼嘗試,是我們放棄了「輸入完成檔必須有98%以上的正確率」的要求。因為,輸入之後接著與校對流程銜接,而在校對方面我們有重大突破(以下詳說),可以不再需要於輸入時耗用大量力氣來完成輸入檔。這些OCR初步辨識之後的可能錯誤,可以留待校對階段時輕鬆解決。
尋求根本解決之道
今年五月二十七日,於國家圖書館所舉辦的「台灣史料數位化研討會」上,李錫堅教授介紹了他所研發的「佛典大藏經辨識系統」。李教授特針對大正藏這個辨識素材,在所辨識字形模組構成上研究,可以避開前述的日本讀音符號,順利做好字形切割,甚至圈點亦可各別切割出來正確辨識。
而在透過溝通與了解下,發展丹青OCR的力捷公司也同意給我們協助,打算設計一個特別版本,期望將大正藏常用字形及慣用詞庫建立起來,並試圖解決雙行小字的辨識問題。
如果能夠在所辨識的字形模組下功夫,相信不但是大正藏,即使是其它目前辨識軟體無法處理的藏經素材,也是可以迎刃而解的。
四、校對方面的重大突破——檔案比對、看圖校對
恕在下筆拙,還是偷懶的先引一段今年元月的信件內容:
一般都會以為,檔案只要經過傳統人工四校,就算已經校對完成;如果看到別人已經做了三校或四校,就覺得自己不用再校了,再校下去便是資源浪費。其實不然也,若以人工校對,其校對工作是永無止境的。
幾年前筆者負責出版一套《八十華嚴》,經過三校,印成書後,自己看了都臉紅,隨便翻翻都可找到錯漏(怎麼校對的當時沒發現呢)。所以,校對是重頭戲,君不見,連旗標的電腦書都要經過七校,何況是我們手下的藏經文字。
檔案比對,以四阿含來說,假設有A、B兩份電子檔,乃由不同人依據不同書面版本輸入,而A版人工校對較粗疏、B版校對較仔細,但A版保留了大正藏格式、B版則非。這樣看來,兩者各有優劣點。如果兩相比對,B的高正確率可以大大糾正 A版的錯漏,同時A版也可以小小的糾正B版錯漏;而A版的大正藏格式方便對查原書,並可以套用在B版上。所以,最後的理想結果是一個以大正藏格式編排的高正確率經文檔。
當然,整個比對流程還是要付出一番心血——針對差異結果來查書糾錯。但是,這種付出的效率是很高的,不是傳統人工校對可以比擬。希望透過這種方法,我們將來所提供的藏經電子檔,真的可以打出「一字千金」的口號——找到一處錯漏,給台幣一千塊。
檔案比對
幾天前,當筆者將<眾生出版社《四十華嚴》電子檔之檔案比對勘誤報告>提交給王志攀社長過目,他說他們所出版的《大般若經》、《三部華嚴》,每一本都經過十次以上人工校對,但還是苦於有抓不完的錯漏。以眾生出版社出書之嚴謹尚且如此,何況是其它草率從事的出版單位呢!於是,筆者向其表示,光是這些校對人力就很可觀了,如果能夠在作業之初多輸入一、兩個版本(最好以不同輸入法鍵入),然後利用檔案比對來予以訂正,最後再以一次人工校對收尾,應該也可以達到人工十校以上的效果。(以我們最近所完成的大正藏第十冊電子檔而言,其文字錯誤率應可達萬分之一以下。)
檔案比對的要件有二:
1. 同一經文要有兩份以上的電子檔
2. 比對程式
檔案來源
對我們來說,除了自行以OCR大量產生經文檔外,哪裡還會有經文電子檔資源呢?透過網路,可以在台灣、日本網站獲得一部份。經由合作,也可以在台灣各佛教道場及出版社取得一些檔案。更重要的來源是,像蕭鎮國先生,這位朋友以CCCII碼所輸入的大正藏經文已經超過30冊,而且願意提供給我們運用。總之,就我們目前所收集的同一經文重覆輸入之電子檔,可以忙好一陣子來進行檔案比對。
比對程式
中研院資訊所有一比對程式,但不適合輸入格式不一的檔案比對。大概一年多前,我們自行研發了一個深具彈性的比對程式;經過幾次改良,不但能夠處理各種格式不一的經文檔,也可以自訂忽略字元,以及一次比對兩個或三個檔案。依我們目前的作業流程,每份經文至少要有A、B、C三個輸入版本,以來進行一次比對ABC三個,或是分兩次AB、AC兩兩比對。
底下這個範本,是一次比對三個檔案的結果:
T09n0276_p0384a20║無量義經德{{行||性||行}}品第一
T09n0276_p0384a21║蕭齊天竺三藏曇摩伽陀耶舍譯
T09n0276_p0384a22║如是我聞。一時佛在王舍城耆闍{{崛||窟||崛}}山中。
T09n0276_p0384a23║與大比丘眾萬二千人俱。菩薩摩訶薩八萬
T09n0276_p0384a24║人。天龍{{夜||夜||依}}叉乾闥婆阿修羅迦樓羅緊那羅
{{A||B||C}}分別表示A、B、C三個比對經文檔的用字差異。
這樣的結果檔,針對其差異處,我們只要翻開大正藏原書,就可以很快的予以訂正。當然,我們也有一支小程式,可以方便我們選擇哪一組字串正確、或是自行輸入正確字串。(見附圖二)
【圖二】
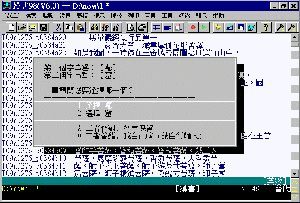
看圖校對
針對比對結果檔,翻書訂正雖然已經很方便,但還有一個更快速的方式,那就是利用看圖校對程式,一邊看大正藏掃瞄圖檔,一邊做文字訂正。(見附圖三)
【圖三】
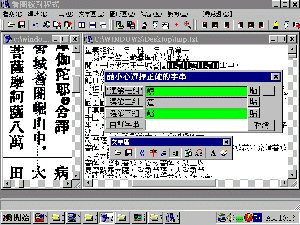
這支程式很厲害,它可以:
1. 同時開啟一文字視窗及一圖形視窗。
2. 在文字視窗中快速移動到比對差異處。
3. 在圖形視窗中秀出相對應的圖形位置。
4. 提供選擇正確字串或自行輸入。
這樣的程式,如果好好發展,不但可以應用在目前的檔案比對訂正上,也可以令往後經文資訊的呈現,除了使用電腦既定字形外,也能夠很方便地看到原書原樣。
意外的收穫
因為是採用不同電子版本來進行比對,從比對差異中,我們常會意外的發現大正藏原書用字錯誤。以大正藏第十冊《八十華嚴》為例,如下:
T10N0279_p0046a15║數世界。有世界。名栴檀寶華藏。{{號佛||佛號}}甚深不
T10N0279_p0046a17║有世界。名現種種色相海。{{號佛||佛號}}普放不思議
T10N0279_p0048b10║海。名天城寶{{蝶||堞}}。世界種。名燈焰光明。以普
T10N0279_p0051a24║十佛剎。微塵數世界。{{興||與}}金剛幢世界齊等。有
T10N0279_p0052c02║或以千土中{{大||一}}切為莊校
每個差異{{A||B}}中,A為大正藏用字,B為其它版本用字。我們在作業當中即發現大正藏在這些地方的用字疑似有誤,經進一步對查高麗藏(K)與磧砂藏(G),結果如下:
K08_p0479b15 佛 G07_p0741c01 佛號
K08_p0479b17 佛 G07_p0741c03 佛號
K08_p0482a17 堞 G07_p0743c13 堞
K08_p0485c12 與 G07_p0746b19 與
K08_p0486c11 一 G07_p0747b17 一
證明我們的發現是有意義的,大正藏原書在這些地方的確是用錯字了。
以我們剛校對完成的第十冊而言,類似這樣的錯誤計有221個。另外,還順便訂正了三百多處圈點的有無及位置。
其它工具程式
雖說是校對,其實在作業過程當中已進行了不少編輯事務。為增進編輯效率,除了善用文書處理軟體的功能外,我們也針對特殊需要撰寫了幾支省時省力的好用程式。但限於篇幅,不能在此為各位詳實介紹,只好略述如下:
1. 大正藏格式化程式:在經文檔每行前面加上大正藏頁、欄、行等資訊。
2. 去除特殊標記程式:去除經文檔中含有類似HTML等標記字串。
3. 檔案合併程式:將一堆小檔快速合併為一大檔。
4. 字頻統計程式:統計經文檔中所用單字及其發生頻次。
5. 特殊標記頻次統計:統計特殊標記間之字串及其發生頻次。
6. 半形及全形空白處理:處理經文檔中不當的空白。
7. 超長行處理:對經文檔中超長的行數提出報告。
8. 字串檢索程式:可檢索折行字串,並列舉其出處前後文。
五、結語
輸入與校對——很簡單的兩個動作,怎麼會有這麼多花樣呢?以筆者這篇文字來講,短短數千言,不就這麼敲敲鍵盤,事後看兩、三遍,就交差了!
可是,當我們期待全套電子大藏經能夠存在於網路上供眾生查詢,也存在於光碟上供大家隨時方便利用,我們就不得不絞盡腦汁來謹慎從事。即使是輸入與校對這等看似不起眼的作業,如有良好及巧妙的技術發展,不但節省可觀的人力、物力,並可大幅提昇經文檔的品質。
筆者對自身目前的工作有一深切企盼——做出高度精確的電子藏經,讓後人不必再把精力耗費在經文的不斷輸入、校對上。期望因緣具足,得以完成這樁不大不小的心願。
(中華電子佛典協會網址:http://ccbs.ntu.edu.tw/cbeta/)
[回gaya首頁]
[佛教圖書館館訊]
[館訊14期目次]