基於XML之新一代Web技術及其在電子出版之應用淡江大學資訊與圖書館學系助理教授 林信成
關鍵詞:XML;HTML;XHTML;Web出版;電子文件;電子出版 |
壹、緒論
隨著網路的發展,圖書與出版技術逐漸由傳統印刷形式,朝向全面電子化的方向邁進,藉由網路,人類的文化得以採用數位化型態即時傳播;透過網路,全球的使用者皆可共享資訊、共用資源。從電子出版的角度而言,Web實為一個建構於Internet上的超文件(Hypertext)出版與管理系統,Web的發展使得超文件觀念普植於人心(註 1)。如今,經由Web產生的電子文件,已經如同蜘蛛網一樣,密密麻麻的組成了一個全球性的分散式超文件系統(Distributed Hypertext System)。在此一系統中,HTML(HyperText Markup Language,超文件標示語言)(註 2)無疑是扮演了一個關鍵性的角色。由於具備規格開放、易學易用、語法簡潔明瞭等特色,加上獨特的超連結,HTML的確為Internet上龐大的數位資料與電子文件,提供了一條有效的整合之道。但是隨著資訊科技的發展,Web應用愈來愈廣泛,HTML的弱點也愈來愈明顯。其中最嚴重的,便是HTML擅長版面編排而欠缺內容語意,所以雖然適合人類閱覽但卻不利於電腦理解;其次,HTML的標籤集是固定的、不可擴展的,無法應付多樣化的應用。這些缺點在電子出版、電子商務、遠距教學、電子圖書館等全新領域急速發展,並期望Web朝向自動化、智慧化目標邁進的同時,遂成了Web發展的一大隱憂。有鑑於此,人們開始著手研究改進HTML的方法,XML(eXtensible Markup Language,可擴展標注語言)便是在這樣的背景下產生的。XML具有可擴展性、高度結構化和良好的資料組織能力,能夠有效的表達網路上各種知識,為資料的交換和處理提供新的機制,一般預料,XML將成為新一代Web的整合技術。若將HTML比擬為網路的第一波革命,則XML極可能繼HTML之後為網路帶來第二波革命性的改變,促使網路從資訊處理階段跨越到知識管理階段,並將在電子出版、電子商務、電子圖書館、電子資料交換、遠距教學等領域展現其強大的應用潛能。眾多的特點使得XML成為一個強勢語言,並迅速獲得各界的支持及響應。然而,XML基本語法雖然簡單,卻由於其可擴展性,目前已發展完備或正發展中的相關技術,如XML Namespaces、RDF、XLink、XPointer、CSS、XSL、DOM、SMIL、MathML......等如雨後春筍般出現,儼然蔚為一支XML大家族,使得XML的複雜度及學習難度遠遠超越HTML。
本文從電子出版的角度著眼,說明電子文件組成要素,分析目前Web出版的現況,從而深入瞭解HTML所遭遇的困境與瓶頸,接著基於文件存取、整合、傳遞、操縱、顯示等議題,規畫一個整合式XML文件管理系統架構,並探討XML相關技術在此一架構中所扮演的角色及功能,進而描繪出Web未來發展之趨勢與輪廓。
貳、電子文件與Web出版
一、電子文件三要素
電子文件所必備的要素眾多,其中最重要的當屬「資料」(Data)、「結構」(Structure)和「表現」(Presentation)三者:| 1. | 資料:指文件的內容(Content),也就是文字、圖表等內涵部分。 |
| 2. | 結構:指文件中有關資料的描述部分,如題名、作者、章節、段落等。 |
| 3. | 表現:指文件所呈現出來的外觀、樣式、版面編排等。 |
若將文件與人體作一類比,則結構就如同人的骨架,資料則相當於肉體,而表現就形同外貌,三者相輔相成,形成一個完整的資訊描述體系,因此在本文中特將此三者合稱為「電子文件三要素」。
一般而言,如果電子出版的目的僅在於如何將電子文件順利呈現在讀者面前供其閱覽,則只要使用適當的「表現」方式來展現出文件的「資料」即可,不太需要考慮到文件的「結構」問題,就此一層次而言,HTML已經相當足夠。但是,如果要更有效的管理、檢索、交換Web上呈現指數成長的電子文件,則非得加強其結構性不可。
二、HTML的限制
HTML是從SGML(Standard Generalized Markup Language,標準通用標注語言)演變而來的。SGML發表於1986年(ISO 8879),主要目的在於規範文件製作及交換的標準,以確保電子文件能在不同的電腦系統上進行交換與應用,它藉由DTD(Document Type Definition,文件型別定義)定義標籤及規範文件結構,作為標注內容的依據,因此SGML具有可移植、可擴展、結構化......等特性,樹立了文件共享的基礎。但由於SGML龐大複雜、不易學習及使用,因此並未獲得普及。有鑑於此,Tim Berners-Lee於1989年提出WWW概念時,乃根據Web 的需求而以SGML定義了適合超文件使用的HTML語言。由於HTML具備規格開放、易學易用、語法簡潔明瞭等特色,加上獨特的超連結功能,使得HTML在短短數年內迅速普及,如今Web上的大多數文件,仍以HTML作為主要寫作格式。但是隨著Web應用愈來愈廣泛,HTML的弱點也愈來愈明顯:
| 1. | HTML著重在資料的表現,擅長版面格式、體裁編排,但其文件在語意(Semantic)上缺乏自我描述性。因此,HTML文件較適合人類閱讀卻不利於機器理解。 |
| 2. | HTML是一個固定用途的標注語言,無法根據不同的應用,由文件作者自訂標籤,此種無法擴展的特性也就侷限了它的發展。 |
| 3. | HTML將電子文件的資料、結構和表現三要素夾雜在一起,使其內容「雜質」過多,使得欲從文件中擷取有意義的資訊時困難度增加。 |
| 4. | 內容提供者、版面編排者、資料著錄者對HTML文件所作的任何處理,都必須對原始內容進行更動,不符合資料處理原則。 |
由於HTML有這些缺點,所以發展出許多改善方案,例如借助動態HTML(Dynamic HTML)、Script語言、CGI、ASP和外掛程式(Plug-Ins)等擴增功能,可以完成動態網頁展現、資料庫存取、通訊協定轉換、網路資源整合等,使得近幾年Web大放異彩。不過,這些基於HTML先天缺陷所提出的解決方案,卻也是促使HTML文件愈來愈「不純」的罪魁禍首。現今,在一份HTML文件中,極可能除了文件本文和有關的結構、樣式等標籤之外,尚且夾雜了眾多與資料無關的字型、顏色、外觀等標籤及屬性,再加上Script程式碼和各家瀏覽器廠商自訂的稀奇古怪功能,怎堪一個「亂」字了得。
其實,資訊化社會所感困擾的不是資訊的匱乏,而是資訊的氾濫。如今,以HTML為主的電子文件充斥在網路上,其內容又亂象叢生,不但造成電子資料的氾濫,更引發了資訊檢索的問題。換言之,由於HTML過度著重於形式的呈現,而忽略了以結構化方式組織資料,使得在網路上進行資料搜尋及交換時顯得雜亂而缺乏效率。因此,為了讓使用者在浩瀚的網海中能順利查找到所需資料,資訊檢索技術在這幾年內有許多突破性的進展,而基於資訊檢索技術的搜尋引擎(Search Engines),順理成章的也成了網路使用者查找資料的主要依據。
三、資訊檢索技術的研究
網路所標榜的終極目標,是要使任何人能在任何時間、任何地點,都能獲得所需的任何資訊或服務(註 3),因此提供使用者一個有效的資訊檢索機制,便成為Web出版所應考慮的重要課題。資訊檢索(Information Retrieval,簡稱IR)技術歷經數十年的發展,累積了不少經驗與成果,如索引(Indexing)技術(註 4)、自動文件分類(Automatic Document Classification)技術(註 5)、全文檢索(Full-text Retrieval)技術(註 6)、相關回饋(Relevance Feedback)(註 7)、自然語言處理(Natural Language Processing)及跨語資訊檢索(Cross-Language Information Retrieval)技術(註 8)、多媒體資訊檢索(Multimedia Information Retrieval)技術(註 9)等,近年來由於電腦科技的發展及各領域研究人員的投入,資訊檢索技術漸漸朝向跨領域整合方向發展,如資訊過濾(Information Filtering)、資訊擷取(Information Extraction)、資料挖掘(Data Mining)、智慧型代理人(Intelligent Agent)等,使得資訊檢索成了一個多元化的研究領域。學者Michael Lesk將資訊檢索技術的發展歷程,從1945年起以每十年為一個年代劃分,每個年代都有重要的突破與進展,是瞭解近代資訊檢索技術發展的重要文獻之一(註 10)。
資訊檢索系統的基本原理是(註 11):將文件資料庫中的文件集合(Document set),經由文件分析過程,抽取出足以描述文件的特徵(Feature),以簡化後續的檢索處理程序及提昇檢索效能;當使用者輸入檢索條件時,查詢模組則針對使用者的檢索詞句進行查詢分析(Query analysis),並將此查詢映射(Mapping)至特徵空間,以便進一步與文件進行檢索處理;檢索處理模組經由計算「查詢」與「文件」之間的「相似度」(Similarity)完成比對(Matching)工作;檢索結果最後輸出至使用者的檢視裝置上;若使用者對系統檢索的結果不滿意,可透過互動式的人機介面(Interactive men-machine interface)對系統進行相關回饋(Relevance feedback),以便修正檢索策略,逐漸逼近所需的結果。
在文件分析過程中所抽取出的文件特徵,是不是具有足夠的代表性而能充分描述整份文件,對於整個檢索系統的效能有決定性的影響。回現率(Recall Rate)和精確率(Precision Rate)是評估檢索系統效能的兩大重要指標(註 12),兩者經常是無法兼得的。君不見搜尋引擎動輒成千上百篇的檢索結果,回現率有餘而精確率不足,往往造成使用者資訊需求上的額外負擔;反之,若僅顧及精確率則又往往犧牲回現率。實際上,文件中的結構化資訊,經常是特徵抽取時非常重要的指標,資訊檢索系統在進行文件分析或檢索時,通常可以藉由文件中結構化資訊的輔助,簡化分析過程或提高檢索效能。因此,加強文件的結構性,增加描述性資料,對於簡化文件分析過程,提昇檢索精確率有極大的幫助。以此觀之,在發展全文資訊檢索技術之外,加強Metadata(註 13)的著錄,不失為另一個解決網路上電子文件亂象並提昇檢索精確率的有效方案。
四、Metadata的發展
Metadata是個極為普遍的概念,在我們的日常生活中,四處可見Metadata的蹤影:例如我們可以用{CPU型號, 記憶體大小, 硬碟機容量 ...}(註 14)這一組Metadata來描述每部個人電腦的規格,所以我們可以很清楚的知道配備為{Pentium-II 350, 64MB RAM, 6.4GB HDD...}的A電腦,比起配備為{Pentium 133, 16MB RAM, 1.5GB HDD...}的B電腦來得高檔許多;而對於出版品資料則可用{書名, 作者, 出版社 ... }這樣的Metadata來加以描述。為了讓Metadata發揮更大的功效,於是人們開始制訂各種Metadata標準以供遵循,圖書館長期以來所沿用的機讀編目格式MARC,就是用來描述書目資料的Metadata標準。在網路盛行之後,為了因應既多且雜的電子文件,讓使用者都能儘快而且精確的找到所需資料,陸續被制訂出來的Metadata標準也就愈來愈多。目前已發展成熟或正發展中的Metadata格式眾多,適用於不同的領域及用途,例如:早已普遍使用的MARC家族(USMARC, UKMARC, CMARC)、PICA+等;專為描述科技文獻的BibTex、EELS、EEVL、RFC 1807等;專為描述人文社會科學資源的ICPSR SGML Codebook Initiative、TEI Headers等;專為描述政府資訊的GILS Core Elements;專為描述地理空間資源的CSDGM(Content Standard for Didital Geospatial Metadata);專為描述博物館藏品與檔案特藏的CDWA(Categories for the Description of Works of Art)、CIMI(Computer Interchange of Museum Information)、EAD(Encoding Archival Description)等;以及專為描述大量網路資源的Dublin Core(Dublin Metadata Core Element Set)、IAFA/WHOIS++Templates、LDIF(Lighweight Directory Access Protocol)、SOIF(Summary Object Interchange Format)、URC(Uniform Resource Characteristics)等(註 15)。
在現成的HTML規格中,大部分的標籤都著重於文件外觀及格式之呈現,只有極少關於文件結構之描述者(如
、、......等),加以HTML並不具備可擴展性,使得雖然可以使用標籤在HTML文件中著錄Metadata,但仍不夠理想,XML的誕生正好提供了一個可行的解決方案。參、XML與新一代Web
一、XML緣起與目標
1996年7月「XML工作小組」(XML Working Group)在W3C(World Wide Web Consortium,全球資訊網協會)的贊助下成立(註 16),當年11月提交XML初稿,並於1998年1月10日正式通過XML 1.0規範,成為W3C的一個建議標準(Recommendation)。由於XML具有可擴展性、結構性、自我描述性,並採用資料和樣式分離原則,使其在資料的管理、交換上擁有極為卓越之性能。XML和HTML一樣都是從SGML演變而來的,只不過HTML是SGML的一個應用語言(Application),而XML卻是SGML的一個精簡子集(Subset)。XML將SGML去蕪存菁,捨棄約百分之二十複雜罕用的部分,承襲了其他百分之八十的特點,是以具備了SGML所沒有的簡易性與靈活性,又有著HTML所欠缺的擴展性與結構性。因此,稱XML為主導「第二代Web」(Second-Generation Web)的重要技術實不為過(註 17)。XML的發展將使得許多理想得以實現(註 18):
| 1. | 促進國際化媒體獨立(Media-Independent)的電子出版。 |
| 2. | 允許產業間定義平台獨立(Platform-Independent)的協定來進行資料交換,尤其是在電子商務方面。 |
| 3. | 以某種形式傳送資訊給使用者代理程式(User Agents),使其能在接收之後自動處理。 |
| 4. | 讓人們很容易的便能使用平價軟體來處理資料。 |
| 5. | 允許人們以自己想要的方式顯示資訊。 |
| 6. | 提供Metadata,不但能幫助人們找到所需的資訊,更能幫助資訊生產者與消費者找到對方。 |
不過,XML並不是被發展出來取代HTML的,而是用以彌補其不足之處。XML相較於HTML至少有以下幾個重要的差異:
| 1. | XML文件的作者可以自訂標籤(Tags)和屬性(Attribute),HTML則否。 |
| 2. | XML是屬於一般用途(General Purpose)的標注語言,而HTML則是一種特殊用途(Special Purpose)的標注語言。換言之,XML是一種元語言(Meta-Language),可以用以生成其他語言,HTML則否。 |
| 3. | XML著重於文件的結構,而HTML則擅長於文件的表現。 |
| 4. | XML文件的作者可以選擇性的利用DTD或XML綱要(XML Schema)來確認文件的有效性,HTML則否。 |
二、新一代Web出版之特色與趨勢
依據XML的特性,可歸納出以XML為核心技術的新一代Web出版將具備如下之特色:| ● | 電子文件具備自我描述性 |
| ● | 電子文件更能有效整合 |
| ● | 電子文件更具結構性 |
| ● | 電子文件具備內容和外觀分離原則 |
| ● | 標注語言具備多樣性及可擴展性 |
(一)電子文件具備自我描述性
XML的標籤可根據不同的用途來定義,因此在語意層次上具備一定程度的自我描述(Self-Description)特性,這對於提昇處理程式解讀文件內容的能力與進行自動處理的效率有著莫大的幫助。
圖 1 是一個簡易的XML文件,不論就人的觀點或機器的觀點都很容易理解其資料的涵義。

圖 1 一個簡易的XML文件
(二)電子文件更能有效整合
透過不同的協定轉換,各種不同格式的資料可以轉成XML格式,使得XML在文件整合(Document Integration)方面,扮演了一個通用集成器(Universal Hub)的角色(註 19),而XML的名稱領域、XLink等正是文件整合不可或缺的重要技術。1. 整合功臣:名稱領域
網路上的電子文件可透過XML定義不同的詞彙集(Vocabulary)加以整合。然而,當分散的資源透過不同的詞彙集,在同一份XML文件中被引用或參照時,若是不同詞彙集中使用了相同的元素名稱,此時便產生衝突了。因此,XML進行資源整合時必須注意元素名稱的唯一性問題,XML的名稱領域(XML Namespaces)便是為了解決元素的命名衝突所發展出來的(註 20)。根據W3C的定義:一個XML Namespace是使用URI(Universal Resource Identifier,一致性資源識別碼)(註 21)識別的名稱集,用於XML文件中作為元素型別和屬性名稱。由於URI是唯一的,所以Namespace可以保證文件中所使用的名稱是獨一無二的。
XML Namespace的宣告是由xmlns: 伴隨著一個自訂的前導字(Namespace Prefix)和一個URI名稱(Namespace Name)所構成,亦即:
xmlns:namepace_prefix=namespace_name
例如:

2. 連結機制:XLink
資源整合的另一個重大議題是:如何將資源連結(Link)起來。眾所周知,HTML的錨元素(Anchor Element)和連結元素(Link Element)是目前Web文件的兩個主要連結機制,已經廣泛的使用了許多年了。然而,連結的種類繁多,如基本連結、多向連結、索引連結、節點內註釋連結、IS-A連結、HAS-A連結、蘊含連結、執行連結、自動連結、類型連結等(註 22),HTML的連結只不過是基本連結的一種,還有許多其他類型的連結,是無法使用HTML完成的。因此,XML便肩負了增強連結功能的重任,不過在XML規格中並未定義任何的連結方法來改變HTML的現狀,而是以原有HTML的連結概念為出發點,延伸出更強大的方式來處理連結資訊,此一延伸機制稱為「XML連結語言」(XML Linking Language),簡稱XLink(註 23)。XLink目前仍是 W3C 的一個工作草案(Working Draft),尚未成為建議標準。為了與 HTML 的簡易連結相容,並提供更強的的延伸功能供人們使用,在制訂 XLink 規格時,簡易性、可讀性、延伸性、實用性等,便成了首要考量的幾個重要的設計目標(註 24)。XLink定義了兩種主要的連結:簡易連結(Simple Links)和延伸連結(Extended Links)。簡易連結雖然提供類似HTML的錨元素功能,只需要一個定址器(Locator),只能連結到單一資源,只能作單向連結,不過,卻也具備HTML所沒有的能力,例如可以定義連結的語意、展現、動作、行為等。延伸連結可以連結到不定數量的資源、可以作相關連結的過濾,但需要將定址器元素另外置放在與連結元素不同的集合裡。此外,XLink還提供了延伸連結群組(Extended Link Group),以便建立一個核心文件來集中管理各類連結(註 25)。
(三)電子文件更具結構性
XML具有嚴格的規範以適應廣泛的應用,因而造就了XML文件強烈的結構性,在資料處理和機器理解方面具備了先天的優勢,這也是促使XML迅速成為重要機讀格式的主因之一。
XML文件可根據其結構性概分為兩類(註 26):
1. 完構的(Well-Formed)XML文件。
2. 有效的(Valid)XML文件。
一個XML文件只要合於XML規範中所制訂的語法規則,便可以很容易的具備「完構性」(Well-Formedness);不過,要達到「有效性」(Validity),則除了滿足語法規則外,尚必須遵循某些額外定義的語意才行。XML處理器會根據XML規範中所定義的完構性和有效性來查核文件內容,一旦發現不合規定的文件便會拒絕處理並告知使用者,這對於在網路上進行資料交換與資訊共享是非常必要的--不符合公認標準的資料可以不被接受。
1. 定義文件結構:DTD與XML Schema
「文件類型定義」(Document Type Definition,簡稱DTD)和「XML綱要」(XML Schema)是XML處理器據以確定文件有效性的兩大重要機制。
DTD是沿襲自SGML的技術,主要用途在於定義文件中的元素型態、結構、範圍、順序等,以作為撰寫XML文件的藍本。不過,由於DTD採用的語法規則與XML不同,不支援Namespace,所提供的資料型態相當有限,並且擴充能力不足,於是有必要發展一個類似DTD又能跨越其功能界限的機制,以作為定義文件結構的全新規範。是以W3C便在1999年2月15日發佈一份「XML綱要需求書」(XML Schema Requirements)(註 27),說明DTD不足之處及新制訂的XML綱要規範所必須符合的要求,並在 1999 年 5 月 6 日,首度發佈XML 綱要的工作草案,並歷經多番修訂,預定在 2000 年中旬提交W3C審議,以便成為建議標準(註 28)。
DTD比起XML綱要,具有如下的優點,因此短期內仍有一定優勢:
| (1) | 廣泛的支援:所有SGML和大多數的XML工具程式都支援DTD,許多文件格式也都支援DTD。 |
| (2) | 豐富的經驗:DTD使用多年,已累積許多寶貴經驗。 |
| (3) | 眾多的應用:數以千計應用於各領域的DTD,早已普遍存在供人使用(註 29)。 |
然而,就長期趨勢而言,XML綱要因具有許多DTD所不及的特色,預料將逐漸成為定義XML文件結構的重要技術:
| (1) | 具有豐富的資料型態,如整數、布林、日期......等,並可由使用者自訂資料型態。 |
| (2) | 支援Namespace。 |
| (3) | 使用XML語法規則,因此文件作者不必另學一套特殊規格。 |
| (4) | 設計支援XML綱要的軟體,遠比DTD容易。 |
| (5) | 具有強大的擴展能力。 |
2. 剖析文件結構:DOM文件物件模型
要對XML文件結構及資料內容,進行加值處理或操縱(Manipulation),可以透過W3C制訂的介面標準「文件物件模型」(Document Object Model,簡稱DOM)為之(註 30)。其實DOM並非是針對XML量身訂做的,而是一套普遍適用於類似HTML、XML等文件的應用程式介面(Application Programming Interface,API)。在DOM的規範中,定義了文件的邏輯結構以及存取、處理、操縱文件的方法。藉由DOM,電腦程式可以輕易的建立文件,可以在文件結構中來回穿梭,甚至可以新增、修改或刪除文件中的元素或內容。制訂文件物件模型的最重要目的之一,是在不同的作業平台和應用程式之間提供一個標準的程式介面。因此,W3C所倡議的DOM,是一個語言獨立的規格(Language-Independent Specification),可以在不同的作業系統中,使用任何程式語言加以實現。
由於網路上的資料分別存放在各種異質系統中,而XML以文件方式來描述各種資料的作法,使得DOM成了管理資料的有效途徑。在DOM模型中,文件中的各個元素(Element)都被視為一個一個的節點(Node),而整份文件則被描述成樹狀結構(Tree Structure)。例如,圖 2 是一個以XML撰寫之簡易圖書目錄,若將此XML文件以DOM展開,則形成如圖3所示的樹狀結構。圖中的矩形方塊表示文件中的節點,而橢圓形則為該節點的內容。這樣的資料結構可以很容易的以程式加以處理,如新增、修改、刪除節點等,而這些動作正好就是文件處理所需的各項功能。

圖 2 以XML撰寫之圖書目
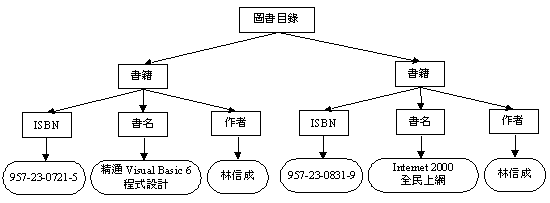
圖 3 以DOM展開之樹狀結構
(四)電子文件的內容和外觀分離原則
XML強調的是如何以適當的結構來組織資料,對於外在的表現則必須透過其他顯示機制才能達成,這就是XML文件的資料、樣式(即內在、外貌)分離原則。這使得文件作者只要專注於內容的撰寫,而將顯示資訊的任務交由版面設計者或使用者,依據不同的需求來展現。如此一來,同一份文件或資料,將可在不同的場合呈現出不同的風貌。一般而言,展示XML文件最簡便的方式是透過樣式表(Stylesheet),一份文件可以使用不同的樣式表而呈現出不同的外觀。CSS(Cascading Style Sheets層級樣式表)和XSL(eXtensible Stylesheet Language延伸樣式語言)即是兩種常用的樣式表語言;此外,XML文件出版者還可以透過分解XML結構樹的方式,將XML文件呈現在讀者眼前。
1. 以CSS層級樣式表顯示文件
層級樣式表(Cascading Style Sheet,CSS)規格分為Level 1(簡稱CSS1)及Level 2(簡稱CSS2)兩種,目前都已正式成為W3C的建議標準。CSS1是在 1996 年 12 月完成,並在1999年1月增修(註 31);而CSS2則是在1998年5月完成的(註 32)。CSS1提供作者針對文件內容設定顯示時的版面格式及樣式,不但便於內容的顯示,而且可以對版面的邊界、邊框、背景及字體種類、大小、形態、字距、行距、對齊方式等進行精細的控制。CSS2則建構在CSS1的基礎上,除了CSS1的功能外還提供了與輸出媒體相關的樣式表,不但可針對不同類型的瀏覽器、語音輸出設備、列表機、盲胞用點字設備或掌上型設備等進行特殊的設定,還提供了更精準的內容定位、字型下載、表格格式、國際化及一些與使用者介面有關的設定。
CSS適用於HTML和XML文件,目前的瀏覽器都已經有支援CSS1,只是程度不同而已;至於CSS2則只支援部分功能。
2. 以XSL可擴展樣式語言顯示文件
XSL(eXtensible Stylesheet Language,可擴展樣式語言)目前仍是一個正在制訂中的規格,W3C於1998年12月提出了1.0版的工作草案,最新修訂版則在2000年1月公佈(註 33)。雖然最終的正式規格可能與目前的草案有所差異,但其理念卻是一脈相承的。
XSL是由XML所定義語言,它提供遠超過CSS的強大功能,雖然CSS發展較早,並可作為HTML文件和XML文件的排版樣式,但卻無法對原始文件進行內容過濾或結構重組,因此,在處理高度結構化的XML文件以及複雜多樣的Web應用時,必須仰賴XSL所提供的功能才能達成。
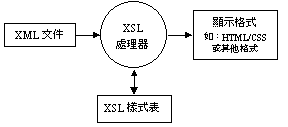
圖 4 以XSL顯示XML文件(註 34)
XSL處理XML文件的過程如圖4所示。其中,XSL樣式表以「樣版」(Template)和「樣式」(Pattern)來描述XML文件的轉換規則;而XSL處理器則負責先將XML文件以樹狀結構建立「原始樹」(Source Tree),接著將樣式與原始樹中的元素相匹配,再根據樣版建立「結果樹」(Result Tree);結果樹便構成了顯示的文件結構。由於結果樹和原始樹是分離的,原始樹可以被過濾、重組或增刪而產生結果樹,因此,目的文件可以擁有和原始文件完全不同的結構。是以使用XSL不僅可將XML文件轉換為HTML文件或其他排版格式,如PDF、RTF、TeX......等,也可以將文件結構轉換至另一個結構。
CSS與XSL的差異為:CSS採用簡單的比對方式,直接將樣式套用在文件上,完全沒有改變原始文件的結構及內容順序;XSL則提供較複雜的機制,可以對原始文件進行內容過濾和結構重組,產生全然不同的文件。下表基於幾項要點,列出兩者的主要差異(註 35):
|
表1 CSS與XSL比較表
3. 以程式剖析方式顯示文件
對於無法使用CSS或XSL完成的工作,可能需要直接以程式剖析XML文件的方式來處理了:首先藉由文件物件模型DOM,建立資料分析、擷取的管道,再利用程式語言的處理能力對資料進行各種加值處理,最後建構使用者介面及資料展現畫面即可。
(五)標注語言具備多樣性及可擴展性
XML既可視為是一種在Web上建立結構化文件和資料的通用格式(Universal Format),也可視為發展其他應用語言的低階語法(Low-Level Syntax)(註 36),這就是XML被稱為 Meta-Language 的原因,也是XML最引以為傲的可擴展性(Extensibility)。目前已有許多經由 XML 所定義並使用於不同領域的應用語言,例如應用於網頁出版的 XHTML(eXtensible HyperText Markup Language)(註 37)、應用於數學方面的MathML(Mathematical Markup Language)(註 38)、應用於向量圖的SVG(Scalable Vector Graphics)(註 39)、應用於多媒體領域的SMIL(Synchronized Multimedia Integration Language)(註 40)、應用於描述網路資源的RDF(Resource Description Framework)(註 41)、應用於網路推播頻道的CDF(Channel Definition Format)(註 42)......等,圖 5 清楚的說明了此一概念,展現了XML無限擴展的能力。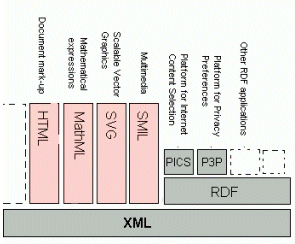
圖 5 XML與應用語言(註 43)
肆、XML在電子出版之應用
一、電子文件與Metadata:RDF資源描述架構
文件整合為資源整合的一環,而資源整合的重大議題之一是:如何使得所有被整合的事物不但是「機器可讀的」(Machine-readable),而且更進一步是「機器可理解的」(Machine-understandable),這和人工智慧(Artificial Intelligent)領域長久以來致力於提昇機器智能的宗旨不謀而合。人類的思維過程不外乎藉由各種管道獲取知識(Knowledge),然後進行推理(Reasoning),最後做出決策(Decision),由此可見,知識乃是人類智慧中極重要的一環。然而,知識的獲得則需要經過資料處理及資訊管理的過程才能萃取出來,如圖 6 所示,大量的資料經過組織、整理後成為有用的資訊;而眾多的資訊經過歸納、演繹之後,才能構成知識;有了足夠的知識,才能做出正確的推理與決策,此乃人類思維的基本體系。因此,要讓機器如同人類一樣能「理解」事物,就必須發展能夠具體表達知識的方式。於是,知識表達(Knowledge Representation)這一門探討如何利用不同模式有效描述人類知識的學問,遂逐漸成為人工智慧一個極重要的研究領域。目前,已被提出的知識表達模式眾多,較重要的有:語意網路(Semantic Nets)、框架(Frames)、生產法則(Production Rules)、劇本(Scripts)、邏輯與集合(Logic and Sets)、物件導向表示法(Object-Oriented Representation)等(註 44)。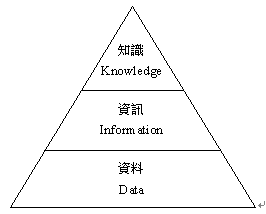
圖 6 知識的構成
網路資源若能有效整合,將建構出人類有史以來最大的知識庫(Knowledge Base),輔助人類進行推理與決策。然而,如今 Web 資料雜亂、資訊氾濫,若要借助機器之功,完成全自動化的資源整合與知識萃取,以目前之資訊科技而言,實仍有許多困難;若要完全利用人工方式,對龐大的資料進行組織與整理,又力有未逮。因此,在撰寫 Web 文件時,由作者或專業人士著錄Metadata,提供足夠機器理解之資訊,實為一可行的方案,而此種萃取文件中Metadata的行為,實際上就是一種知識擷取的過程,所產生的Metadata即是知識的具體表現!有鑑於此,W3C乃大力倡導「資源描述架構」,簡稱RDF(Resource Description Framework),作為處理Metadata的標準模式,使得Web上的應用程式可據以交換「機器可理解的」資訊(註 45)。若是從人工智慧的角度觀之,RDF實可視為一種知識表達,其資料模型(Data Model)將資源(Resource)表示成特性(Property)與值(Value)的關係,相當於「物件-屬性-值」三元表示法(Object-Attribute-Value Triples)(註 46),而用來定義資源與屬性關係的RDF綱要(RDF Schema)(註 47),則類似實體-關係圖(Entity-Relationship Diagram)(註 48)。然而,RDF的宗旨並不在於建立一個專家系統或人工智慧系統,因此,在RDF中並未定義任何的推論機制(Reasoning Mechanism),而僅借助知識表達技術來描述Metadata、建構知識庫,使得系統開發者可以很容易的自行在此知識庫之上建立所需的推論引擎。
在 RDF 資料模型中,所有被描述的事物一律稱為「資源」(Resources),每個資源都擁有一些「特性」(Properties)作為描述其外觀、特徵或屬性之用。描述資源與特性的表示方式則稱為「敘述」(Statement),在一個敘述中包含了「主詞」(Subject)、「述詞」(Predicate)和「受詞」(Object)三部分,可表示成一個三元式 {predicate, subject, object},或簡寫成{p, s, o},此三元式等同於一個起始於端點 s 經由弧線 p 指向端點 o 的有向圖(Directed Graph),如圖7所示。其涵義為「資源s有一個屬性 p,其值是 o」或更簡潔的說法:「s 的 p 是 o」。
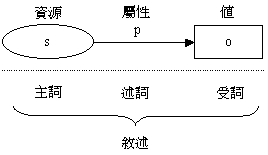
圖 7 以有向圖表現 RDF 敘述
受詞 o 甚至可以是另一個資源而構成更複雜的敘述,例如「 s 的 p 是 s1,而 s1 的 p1 是 o1,p2 是 o2」,則可表示成如圖8的結構化資料模型。
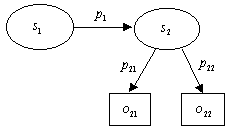
圖 8 RDF敘述之結構化資料模型
由於 XML 文件具有標準化、開放性、結構化及自我描述等特性,因此極適合作為 RDF 的實作語言,如圖9即為實現圖 8 之 RDF 敘述的 XML語法。
在 RDF 中,為了使文件讀寫雙方都能瞭解敘述的含意,必須定義彼此能理解的語彙集,稱為 RDF 綱要(RDF Schemas)。然而,不同的RDF綱要極可能定義了同名的詞彙,以至於一旦同時在同一份文件中被引用或參照時,將造成衝突。為了避免此一問題,RDF 採用了 XML 的名稱領域作為解決方案,如圖 10 所示。

圖 9 以 XML 語法實現圖 8 之 RDF 敘述
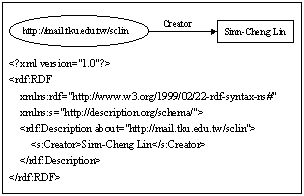
圖 10 以 XML Namespace 區分不同的語彙集
在RDF架構中結合都柏林核心集(Dublin Core,簡稱DC)是描述 Web 文件或網路資源的有效方式之一(註 49)。其用法如圖 11 所示:

圖11 RDF與Metadata:以Dublin Core為例(註 50)
二、電子文件的展示
XML 的整合性及擴充性,使得眾多的 XML 應用語言可以互相結合,展現出電子文件的多樣化風貌,如圖 12 所示。以下針對W3C所提出的 XHTML、SMIL、MathML 和 SVG 等作為電子文件展示用途的規範加以說明。
圖12 XML 使用者介面語言之整合(註 51)
(一)新一代網頁出版語言 XHTML
無論如何,HTML歷經多次的演進,已經擁有支援廣泛 Web 應用的能力,因此目前仍是網路上最通用的Web出版語言。HTML 是 SGML 的一個應用,其最新規範是 W3C 於 1999 年 12 月所發佈的HTML 4.01建議標準(註 52),該標準修正了1998年4月發佈的HTML 4.0規範中的某些Bug(註 53)。在XML規範正式成為 W3C 建議標準之後,HTML工作小組便擬定將 HTML 從原有的 SGML 框架中移植至 XML 框架上的計畫,開始著手將 HTML 4 以 XML 語法重新定義,並於2000年1月頒佈了基於XML之新一代網頁出版語言XHTML 1.0(Extensible HyperText Markup Language,可擴展的超文件標注語言)(註 54)。 XHTML 不但具備了 HTML 強大的超媒體網頁表現能力,最重要的是它擁有XML的整合性及擴充性。 XHTML 支援 XML 的 Namespace ,使得 XHTML 可結合眾多 XML 應用語言,例如:SMIL、SVG、MathML......等,展出電子文件的多樣化風貌。
此外,XHTML 繼承了 XML 的擴充性,並將標籤集依功能及用途加以模組化(Modularization)。網頁作者可根據不同的使用者終端設備或不同的應用需求,選用不同模組的標籤子集;若是現有的標籤集不敷使用,模組化也提供了一個擴充標籤外集的正規途徑。依據 W3C 目前的工作草案,XHTML標籤集依其用途大致分為以下十餘個不同模組:共同字元模組(Common Characteristics of Modules)、基本模組(Basic Modules)、Applet模組(Applet Module)、文字擴充模組(Text Extension Modules)、表單模組(Forms Modules)、表格模組(Table Modules)、影像模組(Image Module)、客戶端影像映射模組(Client-side Image Map Module)、伺服端影像映射模組(Server-side Image Map Module)、物件模組(Object Module)、框架(Frames Module)、Iframe模組、事件模組(Intrinsic Events)、詮釋資訊模組(Metainformation Module)、描述語言模組(Scripting Module)、樣式表模組(Stylesheet Module)、連結模組(Link Module)、基底模組(Base Module)和Legacy 模組(Legacy Module)等(註 55)。
基於未來性的考量,人們除了桌上型電腦(Desk-Top Computers)之外,將藉由更易於攜帶的行動設備(Mobile Devices),如個人數位助理器(Personal Digital Assistants,PDA)、掌上型電腦(Palm-Top Computers)、車用電腦(In-Car Computers)、行動電話(Cellular Phones)、呼叫器(Pagers)......等,來存取網路資訊、瀏覽網頁內容。此一目標必須借助設備描述檔(Device Profile)和文件描述檔(Document Profile)來達成。設備描述檔紀錄著某一已知設備究竟支援了哪些XHTML模組;而文件描述檔則記錄著某一份特定文件要能正常呈現在某個已知設備時,所需要的XHTML文件和樣式表為何,當然,這其中仍須某些轉換程式的輔助,其運作過程如圖 13所示。

圖 13 文件在不同的設備上呈現出不同的版面(註 56)
(二)同步多媒體整合語言 SMIL
雖然 Web 已經成為多媒體文件的重要發行管道之一,但由於先天的限制,HTML 在同步性、互動性和即時性方面一直存在著若干限制。為了提昇 Web 處理多媒體文件的能力,使獨立的多媒體文件能被整合成為媲美電視的同步多媒體節目, W3C 遂於 1997 年 3 月成立了同步多媒體工作小組,基於XML規範制訂了適合 Web 展示的同步多媒體整合語言SMIL(Synchronized Multimedia Integration Language),並於 1998 年 6 月正式成為W3C的建議標準(註 57)。SMIL(唸作smile)語言是一個非常容易學習的語言,它也是XML的一個應用,如同 HTML 文件一樣,SMIL文件同樣可以利用一般簡易文書編輯器來製作。SMIL文件可內含串流語音(streaming audio)、串流視訊(streaming video)、影像(images)、文字(text)或任何其他的媒體類型。SMIL最重要的特性在於作者不但可以描述多媒體文件的時序行為,精確規劃螢幕上的布局,將多媒體物件與超連結相關連,更能設定各種多媒體互動情境,適合在網路上進行即時互動的出版、廣播、教學、娛樂等。
SMIL 的主要特點為:
1. 同步多媒體播放
完美的多媒體環境中,圖、文、影、音等多媒體元素必須能夠依時序同步播放,例如:「播送視頻文件 A 的同時一起播放旁白文件 B 」,或「在旁白文件B播放完畢1秒後接著播放動畫文件 C 」等。Web雖然被標榜為一個多媒體環境,但 HTML 卻缺乏時序上的同步控制機制。 SMIL 可以表述這類訊息,因而可以在 Web 上建立基於時序的同步多媒體播送系統。
2. 簡化創作工具
目前,在 Web 上發行同步多媒體文件,都需要專用的創作工具(Authoring Tools)或者要進行複雜的程式設計。而撰寫SMIL文件則和HTML文件類似,只需簡單的文書編輯器即可,並使用一些簡易的 XML 元素,不用學習複雜的腳本語言。
3. 與 Web 技術緊密結合
SMIL中包括現階段及未來的 Web 技術,如 CSS 樣式表、 HTML 超連結,以及基於 XML 的語法。因此,SMIL可藉由 XML Namespace 整合到其他需要同步多媒體功能的 XML 應用環境中。
4. 提高頻寬利用率
一般而言,視頻訊號是多媒體元素中頻寬需求量最高的。而SMIL的特色是在顯示視頻內容時,可以儘量避免將低頻寬需求的文字、圖片轉換成高頻寬需求的視頻訊號,以提高頻寬的利用率。
5. 促進訊息國際化
SMIL可以滿足多國語言的需求,例如:在同一網頁中包括中、日、英等多國語言的語音文件,然後根據使用者的參數設定自動選擇下載中文、日文或英文版本。
(三)數學標注語言MathML
在科技文獻中,數學公式是非常重要的表現元素,非常可惜的是HTML雖然擁有無數好用的標籤群,然而對於數學公式的支援卻明顯不足,以致於科技文獻的作者只好另謀他法來呈現數學公式,例如利用圖形方式來展現。這造成了三個主要問題:其一,圖形資料量龐大,佔用網路頻寬,影響傳輸效率;其二,圖形化的公式無法重複利用,例如無法編輯或修改公式內容;其三,圖形化公式只適合人類閱讀,機器無法理解公式內涵。這些都使得目前要在Web上傳遞公式內涵或顯示公式畫面都極其麻煩,以致於在Web上進行科技文獻的線上出版困難度增加。有鑑於此,W3C遂於1998年4月提出專為出版數學公式的標注語言MathML(Mathematical Markup Language),並於1999年7月修訂(註 58)。MathML的標籤群可概分為展示標籤(Presentation Tags)和內容標籤(Content Tags)兩大類:展示標籤主要用途在將數學公式外觀以高解析度的方式呈現出來供人類閱讀;而內容標籤則用來將公式內涵以語意化的方式標注,作為不同應用程式之間的傳輸介面,進行分散式科學運算及處理。
(四)向量式圖形標注語言SVG
向量化(Vector)圖形和點陣式(Bitmap)圖形是電腦圖形的兩大類型,目前Web在處理圖形上所使用的標準格式,如JPEG和GIF,基本上都屬於點陣式圖形。為了能增強Web處理向量圖的能力,W3C遂組成工作小組進行向量圖形語言之制訂,並於1999年2月頒佈第一份SVG(Scalable Vector Graphics)工作草案,而最新的草案則於2000年3月公布(註 59)。SVG也是XML的一個應用,主要是作為描述二維圖形的語言,它支援向量圖形(vector graphic shapes)、影像(image)和文字(text)等物件,並允許作者對物件進行群組化、樣式化、轉換和合成。SVG物件可以直接以腳本程式透過DOM來呈現動態及互動式功能,並且由於SVG物件支援豐富的事件控制器(Event handler),如onclick、onmouseover......等,因此可與現有的Web標準相容。再者,藉由XML Namespace,SVG元素與全球其他XML元素可同時整合在同一個網頁中。伍、整合式XML文件管理系統之規畫
綜上所述,XML不但能有效解決目前網路上電子文件的亂象,更有助於開創電子文件自動交換與傳遞的新契機。但是,對於文件的作者、管理者或出版者而言,要區分HTML、SGML與XML已屬不易,至於更深入瞭解何謂「DTD」?何謂「Well-Formed XML文件」?何謂「Validating XML文件」?何謂「XML Schema」?何謂「CSS與XSL」?確實是一大難題。因此,有必要建立一個適合一般使用者使用的「整合性XML文件管理系統」(Integrated XML Document Management System)。此系統不但要具備中文化介面、簡單易用等特性,而且對於不具備任何XML技術素養的使用者,只要經由一般性的編輯流程,即可產出符合XML規範的文件。如此一來,不僅可以解決檢索、管理等問題,更使得電子文件在出版的同時,也具備了結構化資料庫的特性。藉由系統分析過程,本文將此一整合系統劃分為三個子系統,並提出初步規畫結果,以作為未來系統設計之依據。此三個子系統分別是:(1) 編輯子系統;(2) 核心子系統;(3) 出版子系統。其主要任務是基於XML規範,對電子文件的結構、內容、表現三要素,進行有效率的管理以利於展示、查詢、編排、維護等加值處理,藉由各個子系統中的編輯模組、剖析及轉換模組、檢視模組、排版模組、發行模組......等,可以建立一個適用於網路環境的電子文件整合出版系統。
系統方塊圖如圖14所示,其中的Web子系統是供讀者使用的。各子系統之任務分述如下:
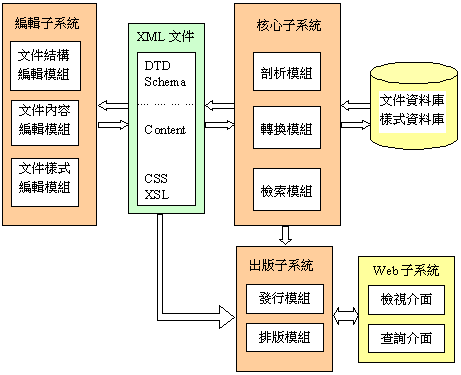
圖 14 整合式XML文件管理系統示意圖
一、編輯子系統(Editing Subsystem)
編輯子系統含三個模組:文件結構編輯模組、文件內容編輯模組和文件樣式編輯模組。(一)文件結構編輯模組
文件結構編輯模組的主要任務是提供一個定義文件結構的途徑,最好具備圖形化的使用者介面(Graphic User Interface),並將使用者在畫面上所定義的結構轉換成DTD或XML綱要,作為驗證XML文件完構性及有效性的依據。(二)文件內容編輯模組
如同一般的文書處理器一般,文件內容編輯模組的任務是提供內容編輯的必要工具,如新增、刪除、複製、剪下、貼上......等,若是文件中尚包含多媒體資料,則還需具備支援編輯多媒體資料的能力。(三)文件樣式編輯模組
文件樣式編輯模組的主要任務在於提供版面和樣式的編排,如字型大小、段落間距、排列方式、字體樣式......,及有關該文件外觀的設定等。然而,由於XML文件不似HTML有內定樣式,必須透過CSS或XSL方式來顯示,因此,文件樣式編輯模組必須有能力將使用者所編排的這些樣式轉換成CSS或XSL。二、核心子系統(Core Subsystem)
核心子系統主要有三個模組,分別是:剖析模組、轉換模組和檢索模組。(一)剖析模組
建立好的XML文件,必須先檢測其語意或結構上有無錯誤才能進行爾後的處理。因此,剖析模組的任務便是依據DTD或XML Schema的定義,檢測文件的完構性及有效性,並將發現的錯誤告知使用者,以便於除錯及修改。目前已有許多公司以API或ActiveX方式提供現成的剖析器(Parser),可作為發展剖析模組之用,如Microsoft的MSXML。(二)轉換模組
轉換模組主要任務是將文件的詮釋資料,依據所定義的結構轉成資料庫方式儲存,其優點是可借助現有資料庫管理系統(DBMS)強大的功能,對文件進行查詢、存取、管理、傳遞等處理。(三)檢索模組
檢索模組是提供一個文件檢索的機制。由於轉換模組已經將文件轉存成資料庫格式,因此只要藉由通用的資料庫檢索方式,如結構化查詢語言(Structure Query Language, SQL),即可很容易的檢索文件內容。三、出版子系統(Publishing Subsystem)
出版子系統主要有兩個模組,分別是:發行模組和排版模組。(一)發行模組
由於數以千萬計的網路使用者已經習慣於使用Web瀏覽器來瀏覽網路文件,網頁也已成了網路資訊傳播的重要管道。所以發行模組的主要目的是將文件以Web方式送到伺服器上。(二)排版模組
既然要以Web方式發行,排版模組的任務便是依據使用者在編輯子系統中,透過文件樣式編輯模組所制訂的格式來展現文件內容。而為了相容性問題,應將其轉換為瀏覽器能接受的排版樣本或標準HTML,以便能順利地在Web瀏覽器上呈現。四、Web子系統(Web Subsystem)
Web子系統嚴格說起來,應可獨立於「整合性XML文件管理系統」之外,因為它是針對讀者設計的,而不是給文件作者、管理者或出版者使用的。它的主要任務是提供Web式的使用者介面,讓讀者可以透過「檢視介面」來閱讀文章;透過「查詢介面」來檢索文件內容。綜上所述,本系統充分運用XML的特性,將文件的結構、內容、表現三要素分開處理,除了可以讓終端使用者順利地瀏覽到文件資料,也可以方便電腦對文件進行查詢比對,更重要的是它可以提供描述文件的metadata,例如:文件分類、作者姓名、文件標題、摘要、關鍵字、編製日期......等項目,這些訊息或許並不是讀者閱讀時的重點,但對於機器在進行資訊檢索的過程,卻具有重大的意義,在工程效率上以及精確率上都將遠高於對全文進行檢索。此外,同一份文件資料更可以隨意加工處理,以各種不同型式呈現出來,創造各種不同的附加價值。
陸、結論與建議
XML能夠有效的表達網路上各種知識,為資料的交換和處理提供新的機制,因此XML將促使網路從資訊處理階段跨越到知識管理階段。從電子出版的角度來看,目前Web上為數眾多的網站及互相糾結的HTML文件,在寫作之初由於缺乏有效的資料著錄,造成資料雜亂、不易檢索的問題,因此亟需資訊檢索技術與方法來解決;此外,除了致力於技術的發展,在寫作及出版的過程中加強Metadata的著錄,亦不失為另一個解決網路上電子文件亂象並提昇檢索精確率的有效方案。XML與生俱來的結構化及自我描述特性,能有效的組織資料、描述資料,以進行語意層次的有意義檢索;而其無限擴展的能力,更使其跳脫既定的框架,而在版面編排、多媒體出版、文件共享......等方面發展出獨特的應用,在在使XML成為網路出版內、外兼顧的有效方案。
從資訊傳播的角度而言,傳播的目的在於建立收送彼此雙方的共同性(Commonness),亦即設法共享資訊(Information)、觀念(Idea)、態度(Attitude)或知識(Knowledge)(註 60)。傳播的雙方可能是人對人,也可能是人對電腦或甚至是電腦對電腦。當網路上兩部電腦透過通訊協定(Protocol)進行通訊時,只不過具備訊息傳遞能力。至於訊息的涵義以及如何把這些訊息轉換成另一種形式呈現給人們,則正是XML的專長。在未來幾年,為因應資訊需求從大眾化到個人化的趨勢,網路上預料將出現更智慧型的搜索引擎,能根據訊息意涵和使用者需求,提供資訊過濾、資訊擷取、智慧型代理等功能,XML技術能夠使這樣的目標早日實現。
從電子商務的角度觀之,不同商業系統採用相同的XML詞彙集,便能隨時自動更新來自各供應商的商品目錄和價格資訊,並根據商品類別為客戶提供最直觀的購物環境。商家之間更可透過金融機構共通的資料交換格式(如以XML制訂的OFX)來交換金融資訊,如電子支付、財務分析、諮詢文件等;圖書館更可利用XML達到自動化的館際合作、館際互借、線上採購等工作。
有鑑於XML將為Web帶來第二波革命(第一波為HTML),目前,產、官、學界無不積極合作,致力於XML相關技術之研究及工具軟體、應用程式之開發(註 61)。我們何其有幸生活在這個科技發達的時代,得以享受新科技所帶來的新產品及新服務,大大提昇我們的生活品質。當然,科技是多變的,未來更是難以準確預測的,我們也可能成為新科技潮流中被實驗的白老鼠。不過,從XML受產、官、學各界關注的程度而言,XML成為下一代Web的整合技術殆無疑義,並將在電子出版、電子商務、電子圖書館、電子資料交換等領域展現其強大的應用潛能,究竟能發揮多少效能,只侷限於人們的想像力及創造力。相較於國外XML技術正如火如荼的發展,國內的研究仍處於萌芽階段,不但中文化的開發工具和應用程式嚴重不足,連參考文獻、研究報告也都寥寥可數,這對提昇國家競爭力無疑是一大阻礙。因此,國內亦應儘速結合各界力量,投入XML相關技術之研發,積極從事推動學術、教育、企業各領域早日採用XML標準,以因應未來多變的網路應用環境。
【附註】
| 註 1: | 超文件是一種依人腦的聯想思維方式,非線性地儲存、管理和瀏覽資訊的技術,文件之間彼此以超連結方式組成文件網路,便於人們「聯想」搜尋,比起傳統文字的線性模式更符合人類的思維方式和習慣。 |
| 註 2: | "HyperText Markup Language", available at <http://www.w3.org/pub/MarkUp/>. |
| 註 3: | 林盈達,《多媒體網路:趨勢、技術、應用》,(台北:松崗,民86),頁 1-1。 |
| 註 4: | Salton Gerard, "A Comparison Between Manual and Automatic Indexing Methods", American Documentation 20:1 (1969), pp.61-71. |
| 註 5: | K. A. Hamil and A. Zamora, "The Use of Titles for Automatic Document Classification", Journal of American Society for Information Science 43:2 (1992), pp.130-148. |
| 註 6: | Salton Gerard, An Introduction to Modern Information Retrieval, (New York: McGraw-Hill, 1983). |
| 註 7: | Salton Gerard and C. Buckley, "Improving Retrieval Performance by Relevance Feedback," Journal of the American Society for Information Science 41 (1990), pp. 288-297. |
| 註 8: | 陳光華,<超越資訊檢索的語言藩籬>,《大學圖書館》,2卷1期(民87年1月)。 |
| 註 9: | 曾元顯,<多媒體資訊檢索技術之探討>,《21世紀資訊科學與技術的展望國際學術研討會》,(民85年9月),可得自<http://blue.lines.fju.edu.tw/ ~tseng/papers/mir.htm>。 |
| 註 10: | Michael Lesk, "The Seven Ages of Information Retrieval". |
| 註 11: | 邱炯友、林信成,《各國政府出版品電子化策略及措施之研究》,研考會研究報告,(民88年6月)。 |
| 註 12: | Robert R. Korfhage, Information Storage and Retrieval, (New York: Wiley Computer Publishing, 1997), pp. 196-199。 |
| 註 13: | Metadata是「用來描述資料的資料」(Data describes other data)或「關於資料的資料」(Data about data),其譯名有「元資料」、「描述資料」、「詮釋資料」......等,並不統一,因此本文直接採用原文而不使用譯文。 |
| 註 14: | {} 為集合符號。 |
| 註 15: | 陳雪華,<網路資源與Metadata之發展>,《圖書館學刊》,12期(民86年),頁 23-28。 |
| 註 16: | 「XML工作小組」最初稱為「SGML編審委員會」(SGML Editorial Review Board)。 |
| 註 17: | Jon Bosak and Tim Bray, "XML and the Second-Generation Web", Scientific American, May 1999, also available at <http://www.sciam.com/1999/0599issue/ 0599bosak.html>. |
| 註 18: | "Extensible Markup Language (XML) Activity", available at <http://www.w3.org/XML/Activity.html>. |
| 註 19: | Jon Bosak, "XML, Java, and the future of the Web", available at <http://metalab.unc.edu/pub/sun-info/ standards/xml/why/xmlapps.html>, 1997.3.10. |
| 註 20: | "Namespace in XML", available at <http://www.w3.org/TR/REC-xml-names>. |
| 註 21: | URI提供一個通用的資源描述方式,包含URL與URN,想要更加瞭解URI的內容可參閱 "Naming and Addressing: URIs, URLs, ...", < http://www.w3.org /Addressing>。 |
| 註 22: | 吳樂南,《多媒體系統:軟硬體、原理及應用》,(台北:儒林,民85),頁 11-16~11-20。 |
| 註 23: | "XML Linking Language (XLink) ", available at <http://www.w3.org/TR/xlink>, W3C Working Draft, Dec. 20, 1999. |
| 註 24: | William J. Pardi原著,鄒正平編譯,《實戰XML—XML in Action》,(台北:微軟,民88)頁 180-182。 |
| 註 25: | 同 24,頁 196-198。 |
| 註 26: | XML 1.0規範中對於完構性(Well-Formedness)和有效性(Validity)有嚴謹的定義,可由以下URL取得詳細說明<http://www.w3.org/TR/1998/REC-xml-19980210>. |
| 註 27: | "XML Schema Requirements", available at <http://www.w3.org/TR/NOTE-xml-schema-req>. |
| 註 28: | 「XML綱要」共有兩部分,第一部分為"XML Schema Part 1: Structures",可在以下URL取得 <http:// http://www.w3.org/TR/xmlschema-1>;第二部分為"XML Schema Part 2: Datatypes",可在以下URL取得<http://www.w3.org/TR/xmlschema-2>。 |
| 註 29: | Robin Cover, "SGML: General Introductions and Overviews, " in The SGML/XML Web Page, 28 June 1999, available at <http://www.oasis-open.org/cover/ general.html#overview>. |
| 註 30: | Vidur Apparao, Steve Byrne, Mike Champion, Scott Isaacs, Ian Jacobs, Arnaud Le Hors, Gavin Nicol, Jonathan Robie, Robert Sutor, Chris Wilson and Lauren Wood, "Document Object Model (DOM) Level 1 Specification Version 1.0", 1 October 1998, available at <http://www.w3.org/TR/REC-DOM-Level-1>. |
| 註 31: | Hakon W. Lie and Bert Bos, "Cascading Style Sheets (CSS1) Level 1 Specification", 17 December 1996, revised 11 January 1999, available at <http://www.w3.org/TR/REC-CSS1>. |
| 註 32: | Bert Bos, Hakon Wium Lie, Chris Lilley and Ian Jacobs, "Cascading Style Sheets, level 2 (CSS2) Specification", 12 May 1998, available at <http://www.w3.org/TR/ REC-CSS2>. |
| 註 33: | Sharon Adler, Anders Berglund, Jeff Caruso, Stephen Deach, Alex Milowski, Scott Parnell, Jeremy Richman and Steve Zilles, "Extensible Stylesheet Language (XSL) Version 1.0", 12 January 2000, available at <http://www.w3.org/TR/xsl>. |
| 註 34: | Microsoft Web Workshop, "XML Architecture", MSDN Online, available at <http://msdn.microsoft.com/xml/ general/architecture>. |
| 註 35: | Jakob Nielsen, "Web Style Sheets", available at <http://www.w3.org/Style/>. |
| 註 36: | 同註 18。 |
| 註 37: | "XHTML 1.0: The Extensible HyperText Markup Language, A Reformulation of HTML 4 in XML 1.0", W3C Recommendation 26 January 2000, avalible at <http://www.w3.org/TR/xhtml1/>. |
| 註 38: | "Mathematical Markup Language (MathML) ", available at <http://www.w3.org/Math>. |
| 註 39: | "W3C Scalable Vector Graphics (SVG)", available at <http://www.w3.org/Graphics/SVG/>. |
| 註 40: | "Synchronized Multimedia", available at <http://www.w3.org/AudioVideo/#SMIL>. |
| 註 41: | "Resource Description Framework (RDF)", available at <http://www.w3.org/RDF/>. |
| 註 42: | "Channel Definition Format (CDF)", available at <http://www.w3.org/TR/NOTE-CDFsubmit.html>. |
| 註 43: | 同註 18。 |
| 註 44: | Giarratano and Riley, Expert Systems: Principle and Programming, PWS-KENT, 1989, pp. 63-102. |
| 註 45: | W3C Recommendation, "Resource Description Framework (RDF) Model and Syntax Specification", 22 February 1999, available at <http://www.w3.org/TR /REC-rdf-syntax>. |
| 註 46: | 同註 44,頁 73。 |
| 註 47: | W3C Recommendation, "Resource Description Framework (RDF) Schema Specification," 3 March 1999, available at <http://www.w3.org/TR/REC-rdf-schema>. |
| 註 48: | 姚步慎,《人工智慧與專家系統導論》,(台北:碁峰,民 80),頁 3-11~3-13。 |
| 註 49: | 都柏林核心集創始於1995年3月,當時OCLC(Online Computer Library Center)和NCSA(National Center for Supercomputing Application)為了制訂一套網路資源的描述格式,乃聯合舉辦了一個研討會,邀集來自電腦、網路和圖書館領域的五十二位學者專家,共同針對Metadata的中心議題,希望制訂一個不但簡易有彈性並且連非圖書館專業人員也能輕易使用的Metadata格式,以便有效的描述網路上多樣化電子文件。基於以上共識,與會的學者們主張先建立一套最小規模的核心資料項,同時擁有意義明確和擴充彈性等特色,於是在1995年的第一次研討會中訂定了13項,而在1996年第三次研討會時,修訂為15項。 |
| 註 50: | 同註 45。 |
| 註 51: | "HyperText Markup Language -- Activeity Statement", available at <http://www.w3.org/Markup/Activity> |
| 註 52: | "HTML 4.01 Specification," W3C Recommendation, 24 December 1999, available at <http://www.w3.org/TR/ html4/>. |
| 註 53: | HTML 4.0建議標準最初於 1997 年 12 月發佈,並於1998年4月修訂,規範內容請參見 <http://www.w3.org/TR/1998/REC-html40-19980424/>, "HTML 4.0 Specification," W3C Recommendation, revised on 24 April 1998. |
| 註 54: | "XHTML(tm) 1.0: The Extensible HyperText Markup Language, A Reformulation of HTML 4 in XML 1.0", W3C Recommendation 26 January 2000, available at <http://www.w3.org/TR/xhtml1/> |
| 註 55: | "Modularization of XHTML", W3C Working Draft 5 January 2000, available at <http://www.w3.org/TR/ xhtml-modularization/> |
| 註 56: | 同註 51。 |
| 註 57: | "Synchronized Multimedia Integration Language (SMIL) 1.0 Specification", W3C Recommendation 15-June-1998, available at <http://www.w3.org/TR/REC-smil/> |
| 註 58: | "Mathematical Markup Language (MathML(tm)) 1.01 Specification", W3C Recommendation, revision of 7 July 1999, available at <http://www.w3.org/TR/REC-MathML/> |
| 註 59: | "Scalable Vector Graphics (SVG) 1.0 Specification", W3C Working Draft 03 March 2000, available at <http://www.w3.org/TR/SVG/> |
| 註 60: | 傳播(Communication)一詞源自拉丁文Communi,意思是「共同」,欲瞭解傳播的正式定義,可參考傳播學者Frank Dance的論文 "The concepts of communication," Journal of Communication 20 (1970), pp. 201-210,其中整理了各家學說,每種皆以一短語標明出不同的主旨。本文對於傳播一詞,則引用徐佳士教授在「《大眾傳播理論》,正中書局(民 76年)」一書中所說明的概念。 |
| 註 61: | 在James Tauber和Linda van den Brink所維護的網站「XMLSOFTWARE」中 (URL: http://www.xmlsoftware.com/),羅列了數以百計由各家廠商所開發的XML軟體,依功能區分為XML Browsers、Conversion Tools、Database Systems、Document/Content Management Systems、DTD Editors/Tools、XML Editors、XML Parsers/ Processors、Publishing Systems、Utilities/Tools/APIs、XLink/XPointer Tools、XSLT editors、XSL formatters、XSLT engines、XSLT utilities、XPath utilities、Search engines等十餘大類,並可連結至原開發廠商獲取更詳細資料。 |
|