創意靈感
--關於電子藏經的輸入、校對及編輯
中華電子佛典協會輸入組及校對組組長 吳寶原
【摘要】:基於數位資訊具有不受時空限制、好查閱、易於應用等特性,漢文佛典資料的電子化工程正持續進行中。本文以中華電子佛典協會成立兩年多來,在電子藏經的輸入、校對、編輯等經驗與大家分享;並從中說明,從事電子藏經出版者,除了瞭解電子資訊的特性、善用現成套裝軟體功能及有資訊部門密切配合撰寫各式工具程式外,最重要的,要能從繁複作業中激發出創意與靈感。文中特就輸入、校對、編輯所產生之創意靈感法寶--檔案比對、看圖校對等工具程式做深入淺出的介紹。
關鍵詞:檔案比對;看圖校對;頻次統計;批次取代
一、前言
感謝歷來祖師大德的努力,留給我們大量的漢文佛典資料,讓後世弟子得以從經文中認識佛法。不過,這些資料幾乎都被編成一本本厚厚的大書,每一本都有相當的重量,都需要空間來存放,查閱及應用上也不怎麼方便迅速。因此,身處這個「數位時代」,我們計劃將書面資料變為幾乎沒有重量、沒有空間,並且好查閱、好應用的電子化資訊。願佛法不受時空限制地流傳下去,以利益更多有情。
中華電子佛典協會(Chinese Buddhist Electronic Text Association,簡稱CBETA)成立兩年多來,面對的是大量藏經的輸入、校對、編輯等問題。筆者帶的團隊(我們總幹事說是「火車頭」),從兩個人發展到現在六個人,目前平均每月完成三百萬個值得信賴的藏經電子文字。這一路走來,成天離不開電腦,對於要怎麼利用電腦來做出又快又準的作業效率,多少累積了一點心得。所以,在明年春天五十六冊《大正藏》電子書完整出版之前,趁此機會先和大家分享一些作業技巧。從某種角度來看,這些技巧比這一套電子藏經可貴;因為,打個比方,後者是魚,前者是釣竿。
二、兩個法寶
進行古籍電子化工作,有一個要點:「在沒有做進一步考據前,書面資料是最大的正確依據。」抓住此一要點,我們發展了兩個「法寶」,並以這兩個「法寶」作為我們整個作業的核心。 (一)檔案比對
對於藏經資料的輸入與校對,就筆者所知,很多佛教單位都只做一次輸入,然後就拿這一份輸入檔進行不斷反覆的校對訂正程序。假設這一份檔案有一萬字,再假設它剛完成輸入時其實有一千個錯字,那麼也就是說它其實有九千個字根本沒問題。可是,這一萬字,不管它客觀上的對錯如何,對於每一校的校對人員來說,他都要瞪大眼睛一個一個去校讀。因此,我們把思考跳開來看,是不是所有的校對人員都浪費了九成的力氣在找錯字呢?如果有一種可靠的方法,可以讓校對者區分「有問題的一千字」與「沒問題的九千字」,那麼只要針對「有問題的一千字」來下功夫,豈不是很妙--這就是檔案比對。
顧名思義,「檔案比對」是指利用程式對同一份文件有兩個或兩個以上的不同檔案版本相互比對出差異。然後,我們假設沒有差異的地方是正確的,而只針對有差異的地方來進行訂正。比如下列這一行經文:
| T08n0251_p0848c07║觀{{自||目}}在菩薩。行深般若波羅蜜多時。照見五 |
我們以{{自||目}}來顯示輸入版本的差異。
只是,這個假設可靠嗎?大家可以來想一想:
| 1. | A將玄奘譯的《心經》輸入電腦,用的是注音輸入;B也將玄奘譯的《心經》輸入電腦,用的是倉頡輸入。 |
| 2. | 輸入者總是傾向將經文正確輸入,若有犯錯,可能是一時疏忽,或是習慣性的拆碼錯誤。 |
| 3. | 大部分地方,兩位輸入者都打對;少部分地方,可能A對B錯,或A錯B對。 |
| 4. | 即使某個字上,AB皆錯,也可能錯得並不一樣。 |
| 5. | 所以,「A對B錯」、「A錯B對」、「AB皆錯,但錯得不一樣」等三類差異,絕對是校對者應予留意的地方。 |
| 6. | 至於「AB皆錯,且錯得一樣,而無法形成差異」,這正是檔案比對的死角。 |
所以,檔案比對也不是百分百的東西。但它這個死角,就我們的經驗來說,一般都是通用字問題。比如,以我們的要求,在輸入資料時,書上印著「僴」這個字,標準的輸入應是[金*本],但我們的比對材料卻經常兩者都輸入「缽」而無法形成差異。這種通用字問題,不難解決,後面有專門解決的妙招。又,假如將比對檔案版本增加為三個,那麼可靠性就更高了;試想,三個人在同一個字上都打錯,且錯得一模一樣,這種機率實在太低太低了。
相對的,人工逐字校對的盲點多得值得同情。怎麼說呢?一來視力疲乏,出錯難免;二來習慣性的認字錯誤,比如「市、巿」、「塵、麈」、「罣、罜」、「妹、妺」、「苟、茍」、「惷、憃」......;三來電腦中文字形的呈現不良,比如「冑、胄」、「祅、祆」、「朏、胐」、「朐、胊」、「朓、脁」、「朣、膧」......,明明每組都是不同的兩個字(內碼不同),但在電腦螢幕上或輸出成報表,字形卻幾乎一樣。上述的第三類盲點,一般人工校對幾乎無能為力,只有透過電腦內碼比對才可以清楚明白。
而就成本考量上,同一份文件多輸入一至二次,划得來嗎?若與整個校對成本一起估算,是不是既省時又省力呢?如果CBETA的經文正確度(與《大正藏》原書相較)沒有過於疏漏(我們事後有再以人工校對過一次,除偶而發現幾個通用字問題外,錯字率應在萬分之一以下),就證明檔案比對確實是一個好方法,不只節省成本,而且比傳統作業方式更能達到高度的文字正確性。
我們使用的檔案比對程式,以及本文提及的許多程式,大都是自己研發設計的。坊間也有一些類似的檔案比對程式,但應用在我們的實務上卻難以施展的,還是自己設計的程式較為好用。
(二)看圖校對
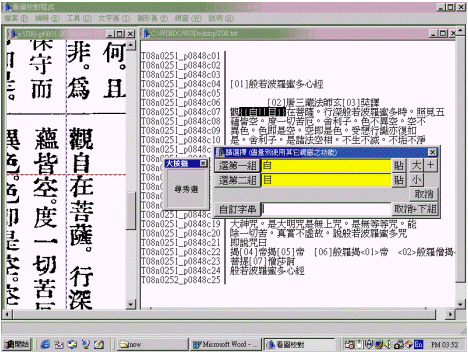
在檔案比對產生差異後,接著做差異訂正。以我們的作業經驗,平均每冊(150萬字)約產生兩萬個差異。早期以翻書方式來逐一訂正,但發覺不夠善巧。於是,經過再三研究,我們的程式設計師構想:「既然經文檔每行都有行首定位資訊,而且《大正藏》原書也已掃描成圖檔,那麼是不是可以利用檔案裡面的行首資訊來秀出相對應的圖檔及位置?」在這樣的靈感下,看圖校對程式於焉誕生。
比如上文曾提及的下列這行經文的差異:
| T08n0251_p0848c07║觀{{自||目}}在菩薩。行深般若波羅蜜多時。照見五 |
在操作時,程式畫面的右邊顯示出包含本行的前後文;而畫面左邊顯示出《大正藏》第八冊第848頁,並且定位在該頁第3欄第7行第2個字;同時會有幾個選擇鈕等候決定。看看下面這個範例圖吧(見圖一),是不是很神奇呢?
這個靈感關鍵在於「文字→圖形」,那麼反過來呢,「圖形→文字」也是一個極重要的創意。我們作業時,偶而會遇到所比對的經文檔全都沒有輸入校勘符號,或是沒有圈點,這是不合我們作業標準的。所以,透過對《大正藏》原書圖檔的結構分析,把這些特殊符號的位置算出來,接著讓文字檔在相對應的地方形成差異,最後再以看圖校對方式判定差異。
對於古籍資料的電子化作業,原書掃描成圖檔,輸入檔每行予以定位,配合檔案比對以進行看圖校對,這正是CBETA在輸入、校對、編輯方面的武功心訣。以下有更廣泛的應用辦法,分別以「輸入」、「校對」、「編輯」三類來詳談。
【圖一】看圖校對程式
三、輸入
(一)掃描
《大正藏》在臺灣有新文豐、白馬、世樺等幾種影印本,總之,在印刷的清晰度上沒有日本原版好。更重要的,《大正藏》本身還經過幾次文字修訂,而臺灣的影印本不一定是根據最新的修訂版本;或是,臺灣的影印本自行做了文字修訂,但卻又不一定修訂正確。基於這些考量,我們採買了日本最新原版來做掃描,而在作業上也同時參考上述各個臺灣版本,因為某些日本原版上的錯字已被臺灣版本聰明的訂正了。
掃描作業很簡單。買一台具有「自動送紙功能」及「自動編號存檔」的掃瞄器,把書拆了,騎縫邊裁切乾淨,送給機器自動作業;如果是做300dpi的黑白掃描,一天跑個一、兩冊應沒問題。然後,事後的圖檔重新命名及歸類,可以簡單寫個DOS批次檔來跑;還有,以圖形處理軟體快速瀏覽圖檔一遍,檢查掃描狀況有沒有大紕漏。最後,當圖檔交給看圖校對人員使用時,經由使用後的圖檔錯誤回饋報告來重新掃描該頁圖檔。
另外,若考慮掃描成果的多重應用,比如我們想同時擁有600dpi及300dpi兩種成果,那麼在掃描之初只做高解析度600dpi掃描即可,然後再以具有批次圖形格式轉換軟體產生另一套300dpi的圖形檔案。也就是,只做一次高品質掃描,再透過軟體來快速產生其他低階格式。
(二)辨識
對我們而言,圖檔的用途除了是看圖校對的必須,圖檔也可以拿來做文字辨識。《大正藏》大體上是適合做文字辨識的,只是某些經文旁邊會有日本讀音符號而干擾辨識,但這可以寫個圖形處理程式來予以去除。許多古籍在行與行間有垂直線,這應該也可以透過程式來處理成辨識軟體可以接受的狀態。
市面上有幾套不錯的中文辨識軟體,我們一直是使用「丹青」,大家可以多比較看看。只是,以《大正藏》的排版及印刷狀況,諸如「雙行小字」、「校勘符號」、「模糊字」、「系統缺字」等,仍難以辨識。所以,就我們的理想來規劃,應該要針對所處理的材料量身訂做一套才是;不過,執行不容易,留待日後再努力吧!
(三)人工輸入
在執行人工輸入作業之初,很重要的一點是「建立輸入規則」。比如本文以外的頁碼、欄位、校勘符號等等該如何輸入,夾注小字、空白字元、空白行怎麼辦,表格怎麼辦,圖形怎麼辦,又有哪些狀況可以不用輸入......等。這裡最令人頭痛的當屬佛典中為數眾多的系統缺字,這將於下文中討論。
為避免檔案比對出現「AB皆錯,且錯得一樣,而無法形成差異」的情況,同一份書面資料的不同人工輸入者,儘量採用不同的輸入法--這是一個小要訣。
(四)缺字
預計五十六冊《大正藏》輸入完畢,會累積約一萬個缺字。過去,缺字問題的確帶來很大的麻煩。甚至現在,也沒有一個十全十美的解決方案。以前大家流行做造字檔,但它頂多只有五千多字的容量;並且各家造字檔不統一,若混合使用,必定造成缺字資訊錯亂。近來流行的自製字形檔,每個字形檔可以有一萬三千多字容量,而且不只可以做一個字形檔;這聽來不錯,不過它必須在類似WORD等具有多字形處理功能的應用介面上使用才行,在純文字環境下不適合使用;所以,若將含有自造字形的資料剪貼到純文字編輯器上,同樣也會造成缺字資訊錯亂。
其實缺字對電腦來說只是一串記錄,只要我們想個辦法將這串記錄唯一化,那麼這個唯一化的記錄就可以代表一個缺字。所以,即使採用"0001"、"0002"、"0003"來表示三個不同的缺字,未嘗不可。只是,當缺字數量不是三個,而是三千個,就不能這樣做了。
CBETA深知缺字處理的困難,我們採取階段性的因應策略。在輸入、校對、編輯等純文字作業階段,我們不用造字檔或字形檔,而是以組字式來表示缺字,如[金*本]、[君/羊]、[匚@僉]、[飢-几+人]等。然後在WORD等具有多字形處理功能的應用介面上,再將所有缺字組字式轉換為unicode及文字鏡字形。所以,組字式是我們記錄缺字的根本,而在這個根本上,就實際應用需要,建立對照表,透過程式快速轉換為適合的缺字表達方式。 (五)詞庫輸入
現在許多輸入法都可以用詞庫輸入,也就是不只一次打一個字,你也可以一次輸入一串文字。像常用的「般若」、「波羅蜜」等詞句,或上述[金*本]、[飢-几+人]等組字式,都可以自行修改詞庫檔來使用。這種方便的輸入設計,不可不知。特別對於組字式的輸入,只要把詞庫建立好,輸入者完全不必在乎它是不是缺字,書上怎麼印,依字拆碼就行了。
四、校對
(一)雙人同工
「雙人同工」是指「同一份工作,由兩個人各做一次」。我們意識到,人是會疲乏而出錯的,即使面對看圖校對這般簡易的工作,平均每個工作者處理一千個差異仍會出現五個判誤。所以,為再減低這千分之五的錯誤率,甲做一次看圖校對的同時,乙也做一次同樣的工作,然後兩人的工作結果再進行比對、形成差異、解決差異。
另外,透過這種嚴謹手段,在實務工作時可以讓筆者知道每個工作人員的作業品質;而其容易出錯的地方,正是教育訓練的重點所在。
(二)集中處理
看圖校對所面臨的差異數量很多,有一個「特殊標記頻次統計」程式可以統計差異頻次,其統計報告摘要如下:(這是三檔比對差異,左邊數字表差異頻次)
1 {{[口*他]||也||[口*他]}}
1 {{[口*宅]||詫||[口*宅]}}
1 {{[口*翕]||蹋||[口*翕]}}
......
76 {{是||是||}}
85 {{妒||妒||[女*石]}}
99 {{&M-023540;||[束*力]||敕}}
144 {{法||地||法}}
188 {{亦||皎||亦}}
227 {{祇||祇||祗}}
總共有10,311個。
參考統計報告,我們可以集中從高頻差異開始下手。比如先處理頻次最高的三項,只要將該三項的差異符號從{{||}}取代為<<||>>即可,然後調整看圖校對程式對差異符號的定義,即可只針對這三項差異來跑。
這裡的觀念重點是「集中」。處理多樣龐雜的差異時,集中才不會分心,集中可以有更高的作業效率。
(三)揭穿相似方塊字的實相
剛才談「檔案比對」時,我們提到「冑、胄」、「祅、祆」、「朏、胐」等難以辨別的相似字。
遇到這類相似字,可以把它們複製到WORD以標楷體24級(或更大)看清楚:
| 「冑、胄」、「祅、祆」、「朏、胐」 |
然後翻字典瞭解其意義,並從前後文義來判斷選擇。
(四)認識佛學名相
我們的作業原則是儘量如實的記錄《大正藏》原文,可是《大正藏》也是人編的,它也會有許許多多的錯誤。所以我們在作業上有所謂的「《大正藏》原文用字勘誤」,如下:
|
T10n0279_p0073c22║ 轉正法[論>輪]入寂滅 乃至舍利廣分布 T10n0279_p0075c14║ 令其捨[難>離]於五欲 專思解脫妙法味 T10n0279_p0121c07║亦如是。爾時金剛[憧>幢]菩薩。承佛神力。普觀十 T10n0279_p0144c28║眼。皆得究竟如來十[方>力]。是為菩薩摩訶薩布 T10n0279_p0230c11║為他演說。令得悟解。終不忘[天>失]。一文一句。如 |
[A>B]中,A表《大正藏》原文用字,B表我們的勘誤。
在這個環節,校對人員對於經文用字遣詞,乃至於義理的瞭解,能有一些基礎是最好的。
五、編輯
(一)善用純文字編輯器
我們(輸入組、校對組)一向使用施得勝先生設計的「漢書」做為文書處理的利器。因為我們在編輯經文檔的過程中,經常需要許多工具程式幫忙,而就程式設計的需要,不管是檔案比對、看圖校對、頻次統計等等,純文字檔是最好的讀入檔與輸出檔。
雖說藏經一冊有150萬字,但以電腦觀點來看,其實一冊只有幾千字,其他的就只是這幾千字在不同地方重複而已。所以,當發現經文中出現一處「鳴呼」這樣的錯誤,透過搜尋及審慎判斷,即可以保證全冊不再發生類似錯誤。如果不是利用電子編輯,傳統的書面出版要從150萬字當中把20幾處的「鳴呼」改作「嗚呼」,是一項艱鉅的任務。
就我們使用上的需要,漢書的「搜尋取代」、「排序」、「巨集」、「區塊處理」帶來極高的編輯效率。比如我們可以特別搜尋行尾含有全形空白的經文行,將這種眼睛看不出來的多餘字元刪除。比如我們對每行第一個經文用字做區塊排序,可以將偈頌行與非偈頌行區隔開來編輯,像這樣:
|
...... T04n0203_p0498c27║[雔/言]我。不得生活。故來相投。以避怨惡。時 T04n0212_p0660b13║[雔/言]伺捕不能得捉。於是頌曰 T04n0192_p0001a13║ 假譬名摩耶 其實無倫比 T04n0192_p0001b18║ 天王金華手 奉持床四足 ...... |
當編輯告一段落,再對行首資訊的「頁欄行」做區塊排序,整個檔案即可恢復正常順序。
此外,對於一再反覆的編輯動作,如我們在處理簡單標記時,「只要某行找到某字元」「就在下一行的某個固定位置插入段落標記」,這寫個簡單巨集就可以把三小時或三天的人工作業在幾秒內用電腦處理完畢。所以,只要是重複性的動作,可以不必一直重複做下去,利用巨集來解決。若巨集也難解,可向程式人員尋求幫助。
(二)批次取代
文書處理器的取代功能,一般侷限在一次做一個取代動作。那如果我們有一百個或一千個取代動作必須執行,豈不是要耗費大量的勞力。所以,一個可以執行批次取代的工具程式是絕對必要的。
在我們的作業中有許多「取代表」,比如「校勘符號取代表一」,如下所列:
[01]=〔01〕
[02]=〔02〕
[03]=〔03〕
......
透過這個「取代表一」,可以讓我們將A檔當中的原有半形校勘符號,在極短時間內自動全部取代為全形。如此一來,只要設定好「比對忽略字元」為0123456789〔〕,等等,A檔就可以和不含校勘符號的B檔進行比對,而其比對結果不會形成校勘符號方面的字元差異。
當比對完畢後,我們再跑另一個「校勘符號取代表二」,如下所列:
〔01〕=[01]
〔02〕=[02]
〔03〕=[03]
......
即可將所有全形校勘符號恢復為正常的半形狀態。
再比如,我們有一個「通用字取代表」,如下:
[(匕/矢)*欠]=款
[(匕/示)*頁]=穎
[(王*巨)/木]=磲
......
透過批次取代程式,就可以迅速得到一個所謂的「通用字版本」。
(三)以看圖替代翻書
在編輯最後階段,我們會執行一次「除錯檢查」。這個檢查程式透過一個特殊格式的取代表,如下:
缽,{{缽||[金*本]}}
鳴,{{鳴||嗚}},,呼
帥,{{帥||師}},文殊,利
佛,{{佛||弗||[佛>弗]}},舍利
......
以下列出可能有問題的經文行:
|
T04n0192_p0019b24║ 精麤隨所得 持缽歸閑林 T04n0192_p0006b11║ 鳴呼世間人 愚惑癡闇障 T04n0204_p0500c06║(七)昔有迦羅越。常願見文殊帥利。迦羅越便 T04n0208_p0533b14║(九)昔有慳貪長者。佛欲度之。先遣舍利 T04n0208_p0533b15║佛。為說布施之福種種功德。長者慳貪都 |
透過上述特殊格式取代表,輸出成差異行:
|
T04n0192_p0019b24║ 精麤隨所得 持{{缽||[金*本]}}歸閑林 T04n0192_p0006b11║ {{鳴||嗚}}呼世間人 愚惑癡闇障 T04n0204_p0500c06║(七)昔有迦羅越。常願見文殊{{帥||師}}利。迦羅越便 T04n0208_p0533b14║(九)昔有慳貪長者。佛欲度之。先遣舍利 T04n0208_p0533b15║{{佛||弗||[佛>弗]}}。為說布施之福種種功德。長者慳貪都 |
注意,對於像「舍利佛」這種折行文字,也是可以檢查出來的。
接著,我們以看圖校對方式迅速判定差異的對錯,而不是利用辛苦的翻書校對。
這裡的工作重點是對於任何值得疑慮的字元,我們可以設法將之形成差異,以利用看圖方式來校對。這個概念是我們對看圖校對程式的充分應用,可以發揮事半功倍的效果。
(四)以程式來做各種檢查
除了上述的「常錯字除錯檢查」,我們陸續設計了好幾支特殊的檢查程式,諸如「行首資訊」(經號、頁、欄、行有沒有問題)、「對稱符號」(如[]、()等符號有沒有不對稱情形)、「標記」(如段落標記是否遺漏)等等,都是很快就得到可能的錯誤報告。在大量的文字海裡,以人工來檢查這些可能的錯誤幾乎是不可能的。
(五)新舊比對
最後,還有一招不得不說。一冊經文檔,從開始到結束,整個處理過程可能要十個工作天,而在這十個工作天中,可能經由二、三個人執行了二十個重大步驟。理論上,每一個處理步驟如果正常執行,那麼這冊經文檔應該愈來愈正確。可是,理論歸理論,不要忘記「人都是會出錯的」。出什麼錯?狀況很多,比如不小心按del鍵刪掉一個字,或不小心按錯鍵而多複製了一行,或用錯取代表......。當發生這些「不小心」時,工作者是完全不知道錯誤的發生。
所以,在執行的步驟與步驟之間,要記得做新檔與舊檔的比對。也就是將這一步驟執行完畢後的新檔,與上一步驟執行之後的那個舊檔,兩相比對,然後統計其差異,觀察有沒有不正常的特殊差異發生。如此一來,即可校正人工錯誤。
六、結語
從以上敘述中,除了看到一個又一個的程式,相信也可以感受到筆者想要表達的「創意靈感」。如何產生這些「創意靈感」呢?就文化事業團體的運作,以筆者個人經驗,以下三項要點謹供參考:
1. 不滿足於既有的作業流程及技巧 2. 堅實的在思考上建立「問題→解決」模式 3. 良好的溝通互動
一、二兩點,很容易明白。針對第三點,筆者的想法是:人的能量是很大的,尤其一個團體所累積的能量更是巨大。這些能量,如果用錯方向,比如拿來保全自我而相互鬥爭,那麼這個團體很快就會垮掉而一事無成。但如果紮紮實實把能量用對方向,少一點個人情緒,多一點無私付出,讓每個人的聰明才智得以相加相成,這條道路才有成果斐然、可長可久的條件。
在協會裡,所有利用電腦來辦事的人,雖不必然要會撰寫程式,但一定要有基本的程式設計想像力;自己不會寫程式沒關係,但可以從繁複的實務作業中提出構想,將理念與程式專員密切溝通討論,以設計出解決問題的工具程式。
「能利用電腦的,我們就努力來利用;要利用人力的,就儘量弄出最省人力的作業方式。」--這是我們資訊組周海文君的銘言。就是對這種精神的體認與貫徹,我們才會有檔案比對、看圖校對,才會有秉持這種精神所開展出來的各種高效率作業方式。
所以,從事電子藏經出版者,若能深切瞭解電子資訊的特性,善用現成套裝軟體的功能,再加上相關部門密切配合撰寫各式工具程式,以及最重要的是,從繁複作業中激發出創意與靈感;而當自以為所有東西都已經在電腦裡面跑的時候,再思考一下上述的這些問題。
《佛教圖書館館訊》九○年度各期主題第二十五期主題:「佛教電子期刊」,截稿日期:二月二十八日。 第二十六期主題:「佛教博碩士論文」,截稿日期:五月三十一日。 第二十七期主題:「佛教圖書分類法」,截稿日期:八月三十一日。 第二十八期主題:「佛教圖書館與母體機構關係」,截稿日期:十一月三十日。 本館訊旨在發展佛教圖書館事業,提供佛教圖書館經營管理之理論及實務作業資訊。歡迎關心佛教圖書館之先進不吝惠賜專論、研究心得與新知報導等文章。 一、本刊各專欄內容如下:
二、來稿以原創性為主,一稿不能數投。稿件涉及版權部分(如圖片及較長之引 文),請事先徵得原作者或出版者書面同意,本刊不負版權責任。 三、本刊對來稿有刪改權,如不願被刪改者,請預先註明。 四、來稿請具備下列項目:1. 中文篇名及真實姓名。2. 服務單位、職稱。3. 學術 論著請附中文摘要(三百字以內)、關鍵詞(五個以內)。 五、來稿刊出後,致贈稿酬及當期本刊三冊,並將同時發行於全球資訊網 (WWW)。 六、來稿請寄:嘉義縣竹崎鄉604內埔村溪州49之1號「佛教圖書館館訊雜誌編輯部 收」。 |