CBGrep資料搜尋工具的介紹
中華電子佛典協會資訊組組長 周海文
【摘要】:當網路上已有許多功能完備的文字檢索軟體時,為什麼中華電子佛典協會要再自行開發一套檢索程式?在此筆者願意將開發時期的構想、思路方向、功能介紹,以及在文字檢索所獲得的些許心得與看法,呈現與有興趣的朋友參考指教。
關鍵詞:CBGrep;資料檢索;中文檢索
一、前言
CBGrep是一個功能簡單的純文字搜尋程式,此程式可在CBETA所推出的漢文電子大藏經光碟中找到,亦可在CBETA網站下載(註1)。當第一次接到《佛教圖書館館訊》邀稿,希望能為此程式寫一篇介紹文章時,不免傷腦筋地搔搔後腦,這東西又不是什麼大程式,隨便幾句話就可以介紹完,怎能寫出文章來?
十月底剛好有機會遇上自衍法師,當面提起筆者的困擾,法師的回答也很有意思:「如果是小程式,當初為什麼要花時間設計?」法師接著說:「聽說你們有許多工具程式都是自行開發,程式設計者與工作同仁的互動很緊密,我們希望藉著這個機會,能多瞭解你們在這方面的互動經驗,分享CBGrep的開發過程,而不是只要CBGrep的使用說明而已。」
仔細想想法師的話,的確提供了不少思路,除了CBGrep各功能的開發因緣之外,筆者也想藉此機會,提供些許個人在資料檢索的心得,讓有興趣的朋友當成參考。
二、為什麼要寫這支程式?
1998年底,那是CBETA成立第一年的歲末,當時決定推出一片光碟,作為該年度的成果發表,內容雖然只有《大正藏》第五冊至第十冊共六冊,卻是我們歷經一年研究出許多不同的工作流程後,所獲得寶貴經驗的展現。由於內容有一套我們所謂「普及版」(註2)的經文,這套主要是依日本新脩《大正藏》的經文格式來設計,而為了讓使用者更能發揮電子經文的功用,最基本的一定要提供資料檢索的功能。
筆者想經常使用電子資料的人應該知道,電子資料在現今的閱讀介面,依然無法取代傳統書籍的地位,但在文字資料的檢索,則有著極大的便利性,當時我們順手收集了一些檢索程式,計有:CTGrep(註3)、Search and Replace(註4)、WinGrep(註5)與Windows Grep(註6),並針對實際的使用進行評估,所發現的問題則在下文一一提出,而這些問題的解決也正是CBGrep所具有的特色。
三、CBGrep資料搜尋工具的開發
(一)中文字的判斷
在Big5中文環境中,一個中文字是由二個「位元組」(byte)所組成,這是所有沒考慮雙位元的檢索軟體首先會面臨的考驗。例如要找「偵」這個字,在本文中就找到不少個,但大部分都不是真正要的。為什麼呢?因為「偵」這個中文字的內碼是「B0 BB」,也就是當資料中連續二個位元分別是「B0 BB」時,就會被判斷為「偵」字,但我們看看「什麼」二字,它們的內碼分別是「A4 B0」與「BB F2」,所以當「什麼」二字被放在一起時,內碼就變成了「A4 B0 BB F2」,這時我們可以看到合併時剛好在二字的中間形成了「B0 BB」,這也就是為什麼許多程式會有誤判的情況發生了。
有人可能認為查詢單一中文字的機會比較不多,在實際的應用上的確是如此,但也不能說完全沒有,況且在檢索二、三個字的情況,也可能會有誤判的情況發生,再者,一個無法正確檢索單一中文字的檢索程式,的確是會有一點遺憾的,而筆者也的確看過不准使用者查詢單一中文字的中文檢索程式呢!
在當時收集的程式中,只有童闓運先生所寫的CTGrep可以正確的判斷單一中文字,其他以英文為主的程式都無法通過考驗,而這一點,卻是我們認為極重要而不可妥協的部分,故理所當然地要將此功能列入CBGrep的首要考量之中。 (二)解決與中文相衝突的特殊控制碼
另一個與中文相關的問題是「控制碼」相衝,在某些英文檢索軟體中,支援一些特殊的控制碼,或是Regular Expression(常規表示法)的命令,以Windows Grep V1.2為例,下列這些碼都有其特殊意義:
\ ^ $ ? : * + - [ ]
如果要搜尋的文字中包含上述字元,則一律要在其前加上倒斜線字元(back-slash)"\",用來表示"\"之後的字是要搜尋用的,不是控制字元,例如要檢索"c:\windows",就要輸入"c\:\\windows"。然而在中文字中,若第二個位元剛好是"\ [ ]"等字元就會出問題,如「觀照」的「觀」,其第二個位元就是"[",此時若想在WinGrep裏檢索「觀照」,甚至會出現"[ ]"沒有成對出現的警告訊息呢!
這要怎麼解決?依規則就是在"["之前插入一個倒斜線字元"\"即可,但那等於是要在中文字的中間插入,一般的文字編輯器並不容易做到此點,而且到底有哪些字會有這些困擾也不易得知。故早期筆者曾為此寫了一個小程式"WinGrep Tool",用來將檢索用的字串轉成WinGrep可以正確接受的形式,例如「觀照」會轉換成「躡[照」,「加行」會換成「功[持」,如此才得以暫時克服這個問題。 (三)關鍵詞折行的狀況
折行是中文文章中常會遇到的狀況,以下面這一段《增壹阿含經》的經文為例:
增壹阿含經十念品第二
(一)聞如是。一時。佛在舍衛國祇樹給孤獨
園。爾時。世尊告諸比丘。當修行一法。當
廣布一法。便成神通。去眾亂想。逮沙門果。
當我們在一般的文書編輯器或檢索軟體要檢索「祇樹給孤獨園」時,就會因為折行的問題而無法順利檢索成功。
在CBETA提供的經文中,Word版(註7)與HTMLHelp版(註8)並沒有這個問題,然而並不是所有的使用者都有Word與使用以IE為基礎的HTMLHelp,因此為了這些使用者,甚至顧及Unix、Mac、MS DOS的使用群,我們也提供了二種純文字的版本,一種叫App格式(註9),其特色是每一個行尾都是一個完整的結束。上面提及的增壹阿含經就會變成如下格式:
增壹阿含經十念品第二
(一)聞如是。一時。佛在舍衛國祇樹給孤獨園。
爾時。世尊告諸比丘。當修行一法。當廣布一法。
便成神通。去眾亂想。逮沙門果。
這種格式雖然方便檢索,但畢竟破壞了經文原本的格式,況且,並不是所有資料都能很方便的轉換成這種格式,故為了遷就極大部分的純文字資料,以及能在標準的普及版上順利檢索,我們還是決定要開發能正確處理折行問題的檢索程式。 (四)特殊的行首資訊
另一個檢索的問題也與CBETA標準的普及版格式有關,以下這個例子才是真正普及版的格式:
|
T02n0125_p0552c08║ 增壹阿含經十念品第二 T02n0125_p0552c09║(一)聞如是。一時。佛在舍衛國祇樹給孤獨 T02n0125_p0552c10║園。爾時。世尊告諸比丘。當修行一法。當 T02n0125_p0552c11║廣布一法。便成神通。去眾亂想。逮沙門果。 |
我們可以看到在經文前有一段固定的資訊,它主要是記載此段經文是出自《大正藏》第二冊,經號125,第552頁c欄8-11行,這些資訊在CBETA是稱為「行首資訊」,這些資訊雖然能讓我們很快的查出經文在原書的位置,但對折行檢索來說,無疑地又是一個大考驗,所以在CBGrep才會有「忽略行首若干字元」的功能,以上述的經文為例,就要設定忽略行首19個位元組(byte),並忽略換行符號,才能順利檢索出「祇樹給孤獨園」。 (五)行首空白
空白包含了全形空白,半形空白與跳位鍵(Tab),這也與CBETA普及版略有關係,在此以《起世因本經》卷一末的「附文」來說明:
|
T01n0025_p0371b01║雅。欲彈則彈。欲舞則舞。欲歌則歌。如是受 T01n0025_p0371b02║樂種種訖已。各隨所之。欲去則去 T01n0025_p0371b03║起世因本經卷第一 T01n0025_p0371b04║ 此經宋藏題為起世經。闍那崛多共達摩 T01n0025_p0371b05║ 笈多譯。進之為前經編入澄函。而丹藏題 T01n0025_p0371b06║ 為起世因本經。達摩笈多譯。卻之為後 T01n0025_p0371b07║ 經。今撿開元錄丹藏為正。故題加因本二 T01n0025_p0371b08║ 字。譯除闍那崛多。卻之為後經。為取函 T01n0025_p0371b09║ 焉 |
我們可以發現在第4-9行之間,因為此段只是說明,並不是經文,故《大正藏》在排版時略縮一字,而CBETA為了保留此一資訊,亦比照處理,讓讀者可以一眼就看出此段並非屬於正文。此時若想檢索「闍那崛多共達摩笈多」,除了忽略換行符號、忽略行首19個字元之外,還必須有「忽略行首任意空白」的功能,才能順利達成檢索的任務。
其實這種功能並非獨為CBETA經文所設計,有許多朋友亦習慣在每一行行首使用數個空格或Tab來排版,這時有了忽略行首空白的功能,就可以正確檢索出所要的資料了。
至此,搜尋工具軟體的設計,基本的檢索功能已有雛型,但在操作使用上,尚有幾點可以提出來討論。
(六)匯出檢索的結果檔
在實際與使用者的接觸中,發現不少人希望能將所檢索到的資料單獨匯出成檔,甚至列印出來,以便一一對照原書來檢查前後文,看看是不是自己所要的資訊。因為他們查到的資料可能很多,無法長時間在電腦前一一檢查、判斷,更不希望第二天想繼續工作時,又要重新檢索出一大堆資料,然後想辦法找到昨天工作的進度。
因此,CBGrep設計成可以將搜尋到的結果單獨匯出成檔,而新版的CBGrep亦加上匯入的功能,讓使用者可以自行編輯匯出的檔案,將不要的資料刪除,只保留自己想要的成果。早期設計的版本並不支援將結果檔匯入,主要原因是擔心使用者在修改之後,破壞檔案的主要格式,可能會因此造成不可預期的結果,然而因為此功能的確有其重要性,故最後還是決定加入,轉而請使用者在編輯時要多加小心,不要刪去重要的資訊了。
(七)支援參數呼叫
這是有點模仿DOS時代程式的功能,直接在程式中加入支援參數,就可讓CBGrep自動執行並產生結果檔。以下是執行的命令範例:
CBGrep三法印c:\buddha *.txt c:\output.txt 1 1 19 1
這個意思是在符合所有c:\buddha\*.txt的文件中檢索「三法印」一詞,並將搜尋的結果儲存在c:\output.txt中,而範例中最後一些數字的意思,則與前文所提各種設定有關,詳細資料請看CBGrep所提供的說明檔。
為什麼會想到做這個?在早期的版本,並沒有考慮這一點,因為既然是Windows模式的程式,理所當然是使用視覺化操作的介面,後來在其他同仁撰寫的程式中,希望也能呼叫檢索程式,並將結果匯出成檔,以利該程式再做進一步的處理,於是決定加入支援參數功能,如此一來,只要知道如何呼叫及瞭解CBGrep的輸出格式,任何程式都可以利用CBGrep來做簡單的檢索功能,而不用自己寫一套程式。
(八)查詢速度比較
查詢速度也是一項重點,在此列出一些當時所測試的搜尋文字程式,藉以比對CBGrep的效率。
測試環境如后:1. 中央處理器(CPU):K6II 233;2. 記憶體(RAM):128MB;3. 測試資料大小:16MB(大般若經600卷,共281,198行)。
檢索字串一:「阿羅漢」(文中有2,825行含此字串)
檢索字串二:「菩薩」(文中有43,787行含此字串)
| 測試程式 | 檢索「阿羅漢」一詞 | 檢索「菩薩」一詞 |
| CBETA CBGrep V0.4 | 搜尋+顯示2秒 | 搜尋+顯示10秒 |
| 童闓運先生 CTGrep V1.02 (Dos模式,無顯示) |
搜尋1秒 | 搜尋3秒 |
| 陳郁夫教授 龍泉一號V3.5.1 | 搜尋+顯示3秒 | 搜尋+顯示9秒 |
| Funduc Software Inc. Search and Replace V2.92 |
搜尋+顯示5秒 | 搜尋+顯示2分50秒 |
| Huw Millington Windows Grep V1.2 |
搜尋+顯示31秒 | 搜尋+顯示1分13秒 |
| Hurricane Software Inc. WinGrep V3.02 |
搜尋+顯示26秒 | (數量超出15,000,無法查詢) |
對於以上數字,在此有必要加上些許說明:
| 1. | CTGrep是DOS模式程式,故傳統的顯示模式受限於螢幕捲動的速度極大,所以測試時皆將結果導向至檔案中。 |
| 2. | 龍泉一號本身並不是直接搜尋純文字檔,而是資料已做成某種資料庫格式再來處理,但並沒有做成索引檔。 |
| 3. | Search and Replace因為大量使用圖形化物件,故在大量資料的顯示上,花費較長的時間在處理。 |
| 4. | Windows Grep V1.2亦使用圖形物件處理,並有計數、Regular Expression(常規表示法)。 |
| 5. | WinGrep V3.02亦使用圖形物件處理及計數,但此版本有查詢上限15,000筆資料,故無法順利完成「菩薩」一詞的查詢。 |
四、CBGrep的規劃設計
瞭解了各程式的特長,並綜合其優缺點與考慮實際情況之後,決定要朝中間方向進行。也就是放棄花時間(程式設計與查詢資料的時間)的非主要功能,將程式定位在簡單、好用、快速,讓大部分的使用者得以用最簡單的方式快速查詢到所需要的資料,並且享受到圖形介面的便利操作,以及DOS模式的批次操作功能。
事實上,CTGrep本身已有處理中文字判斷、折行、忽略行首特定字數的字元及行首空白的功能,而且它的功能不止如此而已。承蒙原作者童闓運先生的同意,提供原始碼作為參考,筆者才得以將它改成視窗介面的CBGrep,其功能選項與結果呈現如下圖所示。(見圖一、圖二)
| 圖一:CBGrep功能選項 | 圖二:CBGrep結果呈現的畫面 |
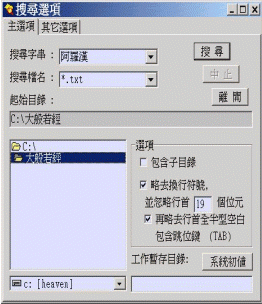 | 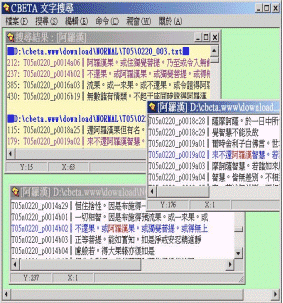 |
五、CBGrep軟體的再造
(一)CBGrep欠缺的功能
CBGrep這支程式因為太簡單了,所以有許多常見的功能並沒有提供,希望日後能有機會與時間再補充,目前僅能略列如下:
| 1. | 搜尋關鍵詞支援Regular Expression(常規表示法)。 |
| 2. | 搜尋關鍵詞支援布林運算。 |
| 3. | 更強大的檔案過濾功能。 |
| 4. | 字數統計:這點曾被刻意移去的,因為筆者認為它的作用不大,而且影響了查詢的速度。 |
(二)突發奇想
在CBGrep的使用者中,最常聽到的建議就是希望能支援搜尋關鍵詞的布林運算,例如想找一段舍利弗尊者與目乾連尊者的對話,就需要查「舍利弗 and 目乾連」,若要尋找任何有關「三身」的資料,可能就要找「法身or化身or報身」,這些功能的確是好用而且是必要的,但一來因為筆者手中的工作一直很多,二來此項技術自己也不熟,還要花不少時間去學習,所以長久以來就一直僅有空想而沒有付諸實行。直到某一次,又有朋友向筆者提出此項需求時,心中忽然有一個靈感浮現:「能否在不改原始程式的情況下,只針對匯出的結果檔來處理?」這樣一來雖然在使用上會感到不便,但卻也能達到同樣的效果,那麼就值得花點時間來試試。
以上述搜尋「舍利弗and目乾連」為例,筆者的想法是這樣的:
先搜尋「舍利弗」,假設出現的行數分別是3,9,16,56,57,99......
再搜尋「目乾連」,假設出現的行數分別是8,12,16,20,60......
這時若我們希望二者差距的行數在四行之內,那麼以下這些配對是合乎要求的:
(9,8)(9,12)(16,12)(16,16)(16,20)(56,60)(57,60)......
若我們希望差距是五行內,那麼以下這些配對是合乎要求的:
(3,8)(9,8)(9,12)(16,12)(16,16)(16,20)(56,60)(57,60)......
根據以上構想,動手寫了一支程式CBGTool,顧名思義即為CBGrep Tool,它的作用就是將二個或三個搜尋結果的匯出檔,依使用者指定的行數範圍來合併成為一個新的檔案,最後再匯入CBGrep使用。
至於“or”的運算,就比較單純了,只要將二個匯出檔直接合併,再去除重複的內容即可。
如此一來,很快速地完成了一個輔助程式,省下了不少修改程式的時間,也達成了任務。但可以想像的是接著而來的問題,本來查詢「舍利弗and目乾連」就可以解決的事,如今卻要分別查二次,並再用另一個程式來整合,然後再匯入,這些手續實在相當複雜,所以沒有進行,暫時無能力改善。
(三)意外的想法,悄悄醞釀中......
不過,在筆者自己的使用過程中,卻意外地發現一些優點。第一個就是大幅縮短了查詢時間。
試著想像下面的情況:在數百Mega的資料中,以十行的差距範圍來檢索「法身and化身」,在花費不少時間之後,才發現資料太多,無從過濾,於是改用三行差距為範圍來檢索,可是結果卻意外地少,於是再改用六行來試試......。想想在極大量的資料中如此一再查詢,是否很花費時間?若能先將「法身」、「化身」、「報身」都查詢出來並匯出成檔,這些資料量已比原先的資料減少許多,此時再進行各種組合來查詢所要的資料,所處理的速度就很快了。
此外,另一個構想,就是可以整理出精要的小型資料庫。例如:有人對「阿羅漢」很有興趣,當他查詢到三千筆「阿羅漢」,可能其中有一千筆幾乎沒有任何重要性。在慢慢整理並去蕪存菁之後,就有了一個二千筆與「阿羅漢」相關的精選資料庫。同理,也可能會有人做出「法身」、「三身」、「無明」、「無常」......等精選資料庫。屆時有了這些資料,當我們想查詢「阿羅漢與無明」相關聯的經文時,就不用每次都埋首在極大量的資料庫中,面對搜尋出來的資料再一一過濾不需要的部分,我們只要挑出「阿羅漢」與「無明」的精選資料庫,再進行分析比對即可。
上述這個構想還沒有成熟,依然在醞釀中,但筆者個人認為很有意思,且極具發展的價值。
以上,就是開發CBGrep的相關思路、構想與心得,提出來與大家分享參考指教。
【附註】
| 註1: | CBGrep下載位置< http://ccbs.ntu.edu.tw/cbeta/download/index.htm >。 |
| 註2: | CBETA普及版經文說明請參考 < http://ccbs.ntu.edu.tw/cbeta/help/version.htm#normal >。 |
| 註3: | CTGrep為童闓運先生所撰寫的文字搜尋程式。 |
| 註4: | Search and Replace為Funduc Software Inc. 所推出的文字搜尋與取代程式。 |
| 註5: | WinGrep為Huw Millington所推出的文字搜尋程式。 |
| 註6: | Windows Grep為Hurricane Software Inc. 所推出的文字搜尋程式。 |
| 註7: | CBETA Word版經文說明請參考 < http://ccbs.ntu.edu.tw/cbeta/help/version.htm#word >。 |
| 註8: | CBETA HTMLHelp版經文說明請參考 < http://ccbs.ntu.edu.tw/cbeta/help/version.htm#htmlhelp >。 |
| 註9: | CBETA App版經文說明請參考 < http://ccbs.ntu.edu.tw/cbeta/help/version.htm#app >。 |
| 註10: | 一個中文字算二個位元組。 |