�y�N���B�����P���ѥ���G
�L�ͥ��Ӻ����W�����ѹB�w
������s�|�y���Ǭ�s�Ҭ�s���@���~��
�i�K�n�j�G���嬰�u��Ъ��Ѳ�´�z��Q�|�v�M�D�t���Z�C�t�����e���T�Ӥ�V�G�������лy�N���������P�o�i�A�䦸�q�y�N�����o�i�ͨ�ݭn����סA�A�ѥ���ͨ�~�ۡA�ݭn�λy���Ӫ��F�A�H�νz�y���p����F���ѡC���t���ó��i�b�u��a�Ʀ���íp���v���Ұ����y���y�Эp���A���O�o�譱���@�Ǭ�s�C
������G�y�N���]Semantic Web�^�F����ס]Ontology�^�F���J�����]WordNet�^
�@
�@�@���ѫܺa�������|�ӻP�U��бСA�o���I�۴q�ۮ��C�]������±б¤w�g���L�y���O���ۡA���ۭn�渨�A�渨���F����S�������ۡA���Ȧ��I�˥��v���C���L�A����±б����F�ܭ��n���@�I�A�N�O�b���Ѫ��F�W�ڭ̤�������y���C���M���ڭӤH���Ъ����Ѩƹ�W�ͤ��W�z�ιB�w�A�O�@�Ӫ��~�~�F���쩳�@���q�ƻy���Ǫ��u�@�A�̪�����ߪ��@��ij�D�S��o�ӷ|ij��ij�D�O���I���Y�A�ҥH�S�O�Ӹ�U��бСC�ڪ`�N��b���Ѫ�ij�D�̭��A���X�g�峹�S�O��ڤ��ѷQ�V�U��бЪ��M�D�����A�ӥB����`�J���Q�סCĴ�p�������Q�б°W�N�Q�׳o�ӥ�����˦b���ΡF�ڶ��ۥ��б¨��g�峹���D�D�ϸ̭��]�O�@�ӥ�����Ѫ��F�覡���Ϊ��@�ӹ�ڨҤl�A�ӥB�B�Φb�u�ȮN����v���@�Ӻ����̭��F���M�٦����j�����ɤk�б¡A�@�ӫ�²��B�ܧ��㪺��Хv����ת��ѵ��c�C�Ѧ��ݨӡA�ӤH�~���DzL���ѥu���U�찵�D�`�j�������СA�ƹ�W�o�X�g�峹�]�\�൹�U���`�J���Q�P��K�����ҵo�C
�@�@���Ѻt�����覡�j�����T�Ӥ�V�G�Ĥ@�Ӥ�V�A�����лy�N���������P�o�i�A�q�y�N�����o�i�ͨ�ݭn����סF����פ���A�N�^�쥻�۩M�~�ۡA�~�ۻݭn�λy���Ӫ��F�A����y�������F���ѡF�̫�p�G�٦��@�I�ɶ����ܡA�N��U����i�ڭ̦b�u��a�Ʀ���íp���v�̭��Ұ����@�ӻy���y�Эp���A���O�o�譱���@�Ǭ�s�C
�q���]������y�N��
�@�@�p�G�U��S��ť�L�y�N���A���N�OSemantic Web�C�U��p�G���D�A���ڬO�������F�A�мȥB�e�ԡC�p�G�U��S��ť�L���ܡA�o�O�̪�@�ӫܭ��n���o�i�A�b�����W���o�i�C���{���q���]������y�N�ASemantic Web�W�O�@�ӷs���������e�Φ��A�����q���z�Ѩ䤤���y�N�A�ե��a�ӷs�@�i���������R�I�]�N�O���������줵�ѡA�����̨��H�j�a�{���N�O��Semantic Web���C�o�g�峹�Ĥ@���o���O�b2001�~���몺Scientific American�]��Ǭ���H�^�W�C�h�~�]2001�~�^����o�����^����A�V���@�ɫŧi�o�ӷs��V�F���~�]2002�~�^�K��Ѱ��i�դh½Ķ�A�ڰ��խq�A�X���b���~�m��ǤH�n���K�븹�]�Ĥ����^���q�q���]������y�N���r�]The Semantic Web�^�C�ҥH�W�Ҧ������y�N������s�A�Үھڪ��N�O�o�g�峹�C�@�̬�Tim Berners-Lee�A�f�ǧ��C�L�N�O�o�����ں������y��T���]World Wide Web, WWW�^���H�C�H�U�����ХD�n�O�ޥγo�g�峹�C
�y�N���N�����U�@�N�����ں���
�@�@�o�O�@�Ӥ���˪��o�i�O�H�Ĥ@�ӡA�L�D�i�û{���y�N���N�����U�@�N�����ں����C�ڭ̭责��L���O���ں����o���H�A�]���L������o�i���ŧi�A���i�����C�y�N�����o�i��V�ëD�S���H����F�p��ޤ譱���H�A�ܦh�H���L�����O�Ѥ�]�ӡA���i�ন�\���A�N�p����L���ʥ��y��T���]WWW�^�ɡA���H�����i�ন�\�@�ˡC�]�\�@�ǥL�ӤH�������Ӹ`�O�ݭn�O�d�A���O�L������o�i���������i�����C�⪾�Ѥ��e�[�J��������V�O�@�w�n������V�A���ޱN�Ӻ����T�����Φ�����A�O���O��L�ҫŧi�������@�ˡA�ڭ̥����n�ӰQ���G�b�o�ӵo�i�W���A�ڭ̺����W���H��A�]�A��СA���Ѩ��æp��]���H�p�G���A�L�Q�~�����A��Ӻ������������ܤF�A����ڭ��٦b�Ͳ{�b���������Ѩ��áA�ڭ̴N�|����A�ڭ̪����ѴN�|�Q�^�O�C�]���A�ڭ̥����w��������N�Ӫ��o�i�A�ӥB���Ҧ]���C
�q�u���y��T���v��u�y�N���v
�@�@����L�{�����y��T���M�y�N�������@�˪��O�H�L�{�����y��T�����u�O�H�̥洫�����]media�^�A�䤤����T�O��������۰ʹB�Ϊ��F�]�N�O���A�L�{���{�b�������W�A�ڭ̥洫���ɡA�u�O�H�����W�h�A�b�������Y�@�ݡA�t�@�ӤH���U�ӡC�ڭ̥ΨӰ���u�@���q���A�����ݭn�F�Ѥ���e�C�ƹ�W�A���������h�F�Ѥ���e�A�������D�o�Ӥ�����O����C�������o�Ӥ�O�H�O�ھڧڭ̪��@���D�ءB��]��ơA�ڭ̹����L���y�z�C�����]�q�̭��A���ެO���m�B�ϧΡB�Υ����ɮסA�̭��]�q�����e�O����H�q���O�����D���A���O�⥦�����@�ӳf���ӹB�e���C�o�ӹ��{�b�ҿת����y��T�����j�����y�z�A�O���T���A�O�ܦ��Ī��@�Ӹ���C����L�Ʊ椰��˩O�H�L�̧Ʊ满�A�p�G�ڭ̰w��q���A�W�[�M�����ѵ��q���\Ū�������A�ڭ̴N�i�H��{���������ഫ���u�y�N���v�C�ҥH�A�L��y�N�����N��N�O���A�p�G�ڥ�i�h����ƹq���ݱo���A�q���N�i�H���O���Ʊ��A�o�O�L���@�ӷQ�k�C
�q���p��\Ū�y�N�H
�@�@�q���p��\Ū�y�N�O�H�b�L���Q�k�B�[�c�̡A���b���U��]���ܦh�O��o�ӫܼ��x�F�A�Ĥ@�ӭn�Q�θ귽�y�z�[�c�]RDF, Resource Description Framework�^�P�q�θ귽�лx�X �]Universal Resource Identifier, URI�^�s������������귽�C�o�O�{�b�����W�ܦh�w�g�b�Ϊ��F�C�j�a�Ϊ�HTTP����}�A�N�OURI���@�ءC�ܦh�H���F��]��ƥH�~�A�]�}�l�θ귽�y�z�[�c�Ӵy�z�����̪����Ѥ��e�A�o�O�@�Ӥj���[�c�A�A�n�b�����W���Y�ӯS�w���귽�A�����S�����D�C�ڭ̳W�w�j�a�γo�Ӥ覡�y�z�A�����Ѹ귽���e�A����A���A�n���귽�A�øg�ѶW�s���s���줧��A�̭��n���\Ū���I�b���̡H�O�n�Q�Ϊ��ѥ���]Ontology�^�өw�q������A�ð�����z�C
���ѥ���]Ontology�^
�@�@���I�O�A�C�@�Ӻ����A�C�@�Ӹ귽�W���n���@�Ӧۤv�w�q��Ontology�A�N�O���ѥ���C������n�o�˰��H�P�@�ӵ��A�b���P�����̡A���P���ɥN�̡A���P���Ϊk�W�A�����N�q�N���@�ˡC�ҥH�A���U�������j�M�`�|�o�Ϳ��~�C�W�AĴ�p�A��@�Ӫ�l�A����]�\�����O��Ъ��u�����J��l�v�A�A�n�����O��Ъ��F��A���A��쪺�i��O�Ӫ����F��A�]�����Ϊ��O�P�˪��y���C�����ä����D�C�Ӻ����귽�Ϊ����ݩ���ӻ��C�ҥH�����j�M�̥����n�w�q�o�ӵ��N������N�q�A�ݩ���ӻ��C�b���@�Ӻ����̭��A�C�@�ӵ����w�q�O����A�N�������ѽd��P�[�c�O����A�N�O�o�Ӻ��������ѥ���n�i�D�A���C�ҥH�A�L���Q�k�O�A�p�G�����W�Ҧ����귽�����@�ӫŧi�A�i�D�C�@���ӳX�������A�o�Ӻ����̭����Ѫ��w�q�O����A���Ѫ��[�c�O����A����q���N�i�H�\Ū�C�Ӻ����C
�@�@�ڭ̭�~�w�g�y�L���쪾�ѥ���O����F���O�����@�Ӻ����귽���Ѥ��e�θ�T�[�c���y�z�M�w�q�C�ӥB�y�N�����c�Q�Ʊ檾�ѥ���O��RDF�������A�������y���g�������A�M���w�q�������Y�M���z����W�h�C�ڭ̪`�N��o�̡A�L�{������Ӭ[�c�A�Ĥ@�A���y�z���㪺���ѩO�H�A�n�i�D�����A�L�{���o�O�������ݪ��Ӥ��O���H�ݪ��A�ҥH�A�n�i�D�����A�Ҧ��b�o�Ӻ����Φb�o�Ӹ귽�̭��A�����Ƿ����Υ�����������i�ӡC �ĤG�O�q���p��b�����P���������i������z�H���Ǥ���W�ߡH�����������Y�s�b�H�o�O�n�������@�Ӫ��ѥ���C�b�o�̦P�ɴ����j�a�A�Ъ`�N��T�Ǥ���Ontology�������ѡB�T�����[�c�A�P���Ǥ�����ס]�@���q�^����w�q�j���ۦP�C�ҥH�A���ͥ������D�A�u�۪ͬ����D�C
���Ѫ��t��
�@�@�ھڬf�ǧ������k�A���Ѫ��t�Ƨ��n�C���ѥ��鰣�F�b������T�W���㪺���Υ~�A�L�{���n���O���@�Ӫ��Ѻt�ƪ��N�q�s�b�F�{���p�G�]�p�o���A�y�N���N���U��H�����`�骾�Ѻt�ơC������y�N���|���U��H���`�骾�Ѫ��t�ƩO�H�]�����������ѥ��鴣�ѤF���P������t������y�z�F�]�N�O���A���ڭ̦b���@�Ӧ�Ъ��Ѻ������ɭԡA�ڭ̧��Ъ��Ѫ��@�����Y�M���Ѭ[�c�@�@�Ӵy�z�C�p�G�����Ѱ��]�j�a�w�g��ҿת�����ת��@�k�B�y�N������ת��@�k�ܲߺD���ɭԡA�@�Ǥ�����Ъ��H�A�L���Ъ������A�i�J����A�g�L���������Y�����F�ѤF��Ӫ��Ѭ[�c��A���M�N�|�F�Ѧ�Ъ����ѡA�N�i�H�i�J��Ъ��ѻ��C�Ϊ̦A�H�m�����¸g�n���ҡA���ݡm�����¸g�n���ܦh�H�ݤ����A�ڧ⥦�����ѥ���[�c�ذ_�ӡA���ެO�H�ξ����i�J�쨺�Ӫ�����t�̭��A���M�|��e���z�ѡC�]���A�L�{�����P�˪��y���A�N�O��URI�b�C�Ӫ�����t�����T�y�z�F�C�ӷ����P�y�N�����Y�C����A�y�N���N���U��y�N���������q�P������t����X�C�]���C�Ӫ�����t�w�g���@�Ӭ[�c�b�o�̤F�A���o�ǥ������P�n�����A�A�����ܧ�ť�����A�A�{���A���o�ܦ�§���A�ڻ{���A�b��ڧn�[�F���p�G�ڧ�ڪ�������t�i�D�A�A�ڪ��y�N�O�o�ˤl�A�ڪ����z�O�o�ˤl�o�Ӫ��A�A���o��ڪ�������t����A�U�譱���ӥi�H��n���q�A�o�O�L���z�Q�C�]�N�O���A���M��l���]�p�A�j�ժ��ѥ���O���q���ݪ��F�j���ؼСA�o�O�Ʊ�o�]�����H�����Ѫ��t�Τƾ�z�C�����ѥ���i�Q�H���Ҿ\Ū�ϥΡA�����H�̪��ѿijq�����١C
���u��Ъ��Ѳ�´�z��Q�|�v���~���б±M�D�t���]�s��մ��ѡ^ |

�@�@�o�ӷ��M�D�`�ΡC�ҥH�A���ަb�N�W�Φb�غب���Ӹ`�W�A�j�a���U�ؤ��P�ݪk�A���o�Ӥ�V�O���T���A�j���j�a�]�|���o�Ӥ�V���C�j�a�p�G�Q�n�o��y�N���o�譱��ơA�o�̴��ѦU��X��²�檺�J�f�����G�Ĥ@�Ӻ����Ohttp://www.w3.org/2001/sw�A�ڷQ�j�a�ܼ��x�A�N�O���ں������z���c�F���U��http://www.semanticweb.org�A�����y�N�����ӧO�зǦb�o�̥i�H���A�o�w�g�O�@�ӻy�N�����W�߲�´�A���ӧi�D�A������зǡB����Q�k�C�t�~�F�i�H�q�m��Ǭ���H�n�]Scientific American�^���}�]http://www.sciam.com�^���2001�~���맹�����U���F���b�m��ǤH�n���媩�o�����A�ڭ����M��½Ķ�A���èS���b�����W���ѤU���]http://www.sciam.com.tw�^�C
���ߪ����D���@�G�y�N���N�|�ϥΤ���y���H
�@�@�ڭ̬J�M�o�{�����W���o�˪��@�ӵo�i�A�ӥB�O�w�諭�Ѫ����e���F�覡�M�ήe�覡�o�i�A�ڭ̷|���ߤ@�ǰ��D�A�ڭ̷Q�ݻy�N�������̨��H���ߪ��Ĥ@�Ӱ��D�N�O�u�y�N���N�|�ϥΤ���y���H�v�C�bWWW�W�A���M���\�h�y���b�ϥΡF����Ƴ̦h�B�q�Ϊ��ߺD�y���O�^��C�y�N���Τ���y���O�H�ڵ���ӵ��סC�Ĥ@�ӵ��סA�έ^��C������o�����O�H��²��A�{�b���ں����W�j������Ƴ��έ^����I���A�A�n��@�ӥ��@�ɦ@�Ϊ��@�Ӫ��F�y���A���έ^��N�n�F�C�]���{�b���ߺD�F�A���ں����w�g�Фj�a�^��F�C�i�O�A�p�G�ڭ̷Q�o�Ӱ��D�G�Q�~�᪺�����j�a�O�_�٬O���έ^��O�H�]���j�a�ݱo������W����Ƥj�����٬O�ϥέ^��A�b�y�N���������𤧫e�A���G���i�����y���b�����W���귽�q�|�W�L�^��C�i�O�٭n�Ҽ{��X�Ӱ��D�A�ëD�o���¡C��p������ϥΤH�f���w���C�H�U�o�X�ӹw���O�ڭ̳̪���b�x�_�D�쪺COLING2002��ڭp��y���Ƿ|�A�䤤���@�������Q�|�A�Фj�a�w���Q�~�᪺�����P����B�z�C�����_���ͻ��G�u�ڤ��n�Q�~�����A�n�b���~�����E���A���W���C�v�L�n��s�|�۵M�y���ոg�z�P�����w���O�G�u�ڭ̤���O�u�A�{���Q�~�����N����������H�W���C�v�ڭӤH���w���O�G�u�ڤ����D���h�֤H�W���A���ڷQ�b�Q�~�������W���H�f�̭��j�����|�����@�O�����媺�C�v�p�G�Q�~���o�O�Өƹ�A�p�G�����_���ͪ��E���A���W���A���o�E���A���̭����h�֤H�O���^�媺�H�@���F���_�a�I�ڭ̥H���b�ݺ����o�i���ɭԡA�]���ڭ̬ݨ쪺�O�b��誺�o�i�B�H�ά�ޤư�a�����o�i�AĴ�p�ڬw�C�ڬw�A�h�⭿���H�W���A�٬O�έ^��A�]���L�̷|�ǭ^��A�|�ΰڡI���Ѧp�G�ڭ̲��ͳo�ӽ��ܡA�u�����E���A���Τ����A���W�����ɭԡA�L���|�^��ڡI�ҥH�A�����W���ެO�L�s�y����ƩδM���Ϊ��귽�A����N�ܦ��ܭ��n�F�C�S���]�A�L�Q�~�A�L�פH�f��H�f�h�A���E���L�פH�W���C�]���A���f�ǧ����e�����]���G�u�U�@�ӮɥN�������A�@�w�έ^��C�v�O�����o���T���C���M�{�����F�賣�O�έ^��A���p�G�A�W�[�i�Ӫ��s��ϥΤH�ư��h�A�ӳo�ǤH�O�����^�媺�A����H���M�|�ΥL�ۤv���y���A�өһs�y����Ʒ��M�N���O�έ^��A����N�|���Ͱ��D�F�C
�@�@�p�G���O�έ^�媺�ܡA�ĤG�ӵ��O����y�����i�H�C������O�H�]���y�N�����e���G�u�O�a���ѷ��q�A�Ӥ��O�a�y�����q�C�v������@�w�n�έ^��A���ѥ���ֳW�w�@�w�n�έ^��g���O�H�S���H�W�w�ڡI����y���u�n�i�H���F���Ѫ���t�A���M���i�H�C�u�n��������t�b�o�̪��ɭԡA�i�H�����P�y�������A����n�����q�A���Ѫ��橹�C���M�O���W�w���A�p����OWL�BXML�K�K�A�O�j�a���ܼ��x���C�j�a���{���A�y�N�������e�Хܷ|��XML�A�o�j���O�S���D���C�����W�w�@��Ontology Language�A�O�̪�b�o�i�����A�N�O�y�z����ɡA���ӥΤ���y���C���H�{����OWL�A�i�H�WSemantic Web�������ݨ�C�ҥH�A�o���D����ӵ��׳����i��A���O�ڭ̧Ʊ楦�O�ĤG�ӵ��סC
���ߪ����D���G�G�J�M�y�N���D�n�̾a���ѥ���F�S�w�y���P�奻�����Ѻz�٦��ݭn�ܡH
�@�@�J�M�y�N���D�n�O�̾a���ѥ���A�O���Ѭ����A����S�w�y���Τ��骺���Ѻz�٦��ݭn�ܡH�]�N�O���A�J�M�w�g�O�渨�F�A�w�g�ݨ쪾�ѤF�A�٭n���۰�����O�H���ץҡG���M�O���ݭn�C�]�����ѥ��骺�s�b�O�W�ߩ�S�w�y���P�奻���~���C���ڭ̤��ѴN���ݭn�Q�פ����Ъ��Ѻz�աA���媾�Ѻz�աA�ڭ̥u�n�Q�ץ���״N�n�F�A�ڥu�n�⥻��ײΤ@�N�i�H�F�C�i�H���o��ܡH���פA�O���M�ٻݭn�C����~�¦Ѯv�b�Ĥ@���t���w�g���o�D�`�M���F�A�ҥH�ƹ�W�ڦb�o�̬O���ƤF�C�]���C�ӯS�w�y���Τ奻���O�@�ӿW�S��������t�C�]�N�O���A�ڭ̲ߺD�λy���Ӫ��F�@�ǪF��A�H�O�ۭ�����۪��A�����a�o�Ǫ��ۤ~����F�ڭ̪����ѡC��ܤ@�Ӫ��۪��F���Ѫ��ɭԡA�N������۪�����F���D��Ҧ����H�����w�g�F���F�A�����λy���N�i�z�ѤF�A�i�H���q�F�C�b�٨S����F�o�Ӧa�B���e�A���M�Ҧ�������٬O�b���P���y���̭��A�]���٬O�ݭn���T��z���R�@�ӻy���Ҫ��F�����Ѥ��e�A�~����إߪ��ѥ���A�ٻݭn�y���o�Ӥu��A�~��F��o�Ӫ��ѡC�ڭӤH���M�٬O����ͦV��ĤG�ӵ��סC
���ѥ������ܾE �@�@���Ѫ��״I�ʱq��ӨӡH�U�����ӳ��ܼ��x�A�q��ơB���B���ҡB�ڸs�B���|���h�B�C��B�Ǭ�B�ɥN���K�K�A���P��ƪ��I���C�P�����@�Ӧ�g���G�ơA�p��������G�ƻP�I�v�j�v�������G�ơA�L�Ϊ��y�N�B�I���B�G�ƹ�H���O���@�˪��ڡI�]�\�Ҫ��F���N�q�O�@�˪��A���Ϊ��y���BĴ�볣�O���@�˪��C���B�ڸs�B���ҡB���|���h�B�C��B�Ǭ�B�ɥN�����A�A��C�Ӥ��P���a��A���N�Τ��P���覡���C��~�¦Ѯv�w���ڤ@�ǨҤl�A�A�b��B�T�d�~�e���i�����ҡB�B�B��A�]���b�y�����Ѹ̭��A�èS���ҡB�B�B��o�T�˪F��A�u�����������g�C�b�@�ӮɥN�̭��y������������A�|�����P�����F�覡�C�զ����ѥ��骺�������P�A�N�v�T�줸�������N�q�P�������Y�A�i�Ӽv�T���Ѫ��[�c�C �@�@���Ѫ��״I�ʦp����{�O�H�ڭ̭��諸���ѯu���٦b�ܡA�C�ӮɥN�ܡA�C�������ܡA�C�ӻy���ܡA�C�ӾǬ��ܡC�p����{���״I�ܲ��A�S�����������Ѫ��F���@�P�ʩO�H���״N�O�ΨC�ӯS�w���`���@�P���y���P���J�C�ڭ̦b�Ϯ��]�ɡB��T�����ҿת����y���]sub-language�^�A�����ոܴN�O��ܹ��C�C�@�榳��ܡA�C�@�ӮɥN�����ۤv����ܡF������A�N�O�M�~����C�ѥ~���ݡA�h�ݦ�ܡA�ݻy�������F�覡�A�ݥ����M������A�A�N�i�H���D����������t�O���@�˪��C���Ѥ����ݡA��ܥ��O�椺�@�ɻP���q���̾ڻP�зǡC
�ѡ]���Ѫ��^�����y�������� �@�@�ڭ̪��D�]�ݨ��Ӻ������ͦV�A�O�����n����@�ӥH���ѥ��鬰���߳]�p�������C��Ӻ����n��n�ΡA�C�ӭӧO�귽�n���y�q���ΡF�w��U�@�ӮɥN�������A������C�@�Ӹ귽�A�C�@�Ӻ����A�����ѥ��骺�y�z�C���Ĥ@�ӻݭn��V�����e�O���i��@�ӤH���@�q�����Ѭ[�c�A�Y�j�a���P�N�����ѥ�����F�覡�C�]���A�ڻ{���Ĥ@�B�ݭn�غc���N�O�y��������C������o�˻��O�H�]���C�ӻy��������[�c���������ѥ���C�����C�ӻy�����[�c���������ѥ���O�H�]���y���]�A���y���A�i�H���F�Ҧ��]��줺���^���ѡCĴ�p�ڭ̦b�o�ӻ��̡A�b�ͦ�Ъ��ѥΪ��@�dzN�y�A�j�a������F�ѡA�i�H���F��줺�����ѡC�ڭ̩ҥΪ��y���A���U�ڭ̨ӷ��q�A���ܪ̻Pť�ܪ̤������Ѫ��洫�A�q�`�O���Ħӥ��T���C���A�I��@�ӥv�������Ӫ���Ю{�A�p�G�n��L�έ^��ͦ�Ъ��ɭԡA�|���@�I�I���D�A���b��Ъ��Ѥp���̭��٬O�i�H�ͱo�ܦn�C�P�˪��A�p�G���b�x�W���~�h�����A���Υx�W���y�����M�S���D�F�p�G��E�ؤs�h��j�������ͦ�л�줺���F��A�ͪ��ɭ��٤����A�����ͨ�@�Ǥ���ͬ����F��ɡA���G���Ӥ@�ˤF�C�۹諸�A�P�x�W�P�M�ͥͬ��Y�Y�O�D�A���p�G�O�M������z���H�ͦ�A�o�S�|�ܦY�O�C�ҥH�A�C�Ӥp���J�A�C�Ӥp���y���B���y���A�b�j�y���������@�Ӧ@�q�����Ѭ[�c�A�b�o�Ӫ��Ѭ[�c�d���A�洫���ѬO�S���D���C�J�M�y���w�g���ڭ̤@�Ӧ۵M���Ѭ[�c�A�������٭n���X�y�����L���F��O�H�ڭ̥i���i�H�^�Ө��s�O�s�H�ҥH�A�J�M�ڭ̤����D�o�ӥ@���q�Ϊ����ѥ�����ˡA�ڭ̥��q�y���}�l�A�_�X���D�A�b�g�礤�i�D�ڡA�@�ӻy���̭��A�@�Ӧ��y���̭��A�������ѥ���[�c�A�O�j�a�i�H�q�Ϊ��C �@�@�ĤG�A�N�O����H�u���ѥ��骺�ϥΪ̡A���ƥةηǽT�ʡA�����|�W�L�y�����骺�ϥΪ̡C�ڷQ��ثe����A�o�O���T���C���Ѧ��ܦh�H�{��Ontology�n�����F�A��~�����F�o�ܺ}�G����Хv����סA�A���γo�˪�����רӴy�z���Ѫ��H���h�֡H�i�H���F�X�Ӫ����h�֡H�o�Ӽƥص��藍�|�������媺�H�h�A���L�Ҫ��F�����ѽd��A���藍�|��y���״I�C�ҥH�A�o�ǬO�ڭ̧Q�Υ���[�c�Υ��骺�z�סA�Ψӷ��q���@�Ӥ�q�A���O�b�٨S���o��@�ӧ��㪺�z�פ��e�A�y�����ڭ̪��O�̧��㪺�B�̦��Ī�������t�C �@�@�̫�A�y�����饻�ӴN�O�奻���óB�z�����n�귽�C������o�H�]���n������@�Ӥ奻���áA�p�n������A�n���P�q����A�n���M������B���y��嵥�A�O�H�����F�C�u�@���w���F�j�b�F�A�q�o�ǰ��y���귽��{�����@�ӻy������סA�٬O�ݭn�u�@�A���ƹ�W�w�g�O���s�E�Q�A�w�g��̫�@�B�F�C
�p��e�{�y�������ѥ���H
�@�@�b�e���Ĥ@���������i���A�ڧƱ�w���A�U��G���ѥ���b���Ӻ������o�i�W�O���i�ίʪ��A�ӥB�Ʊ�ڭ̵ۤⰵ����ɡA�q�y�����ӴC���C�A�Ӭݻy���C���p�H�ڭ̻{�����ӥε��J�����]WordNet�^�Ӱ��C �@�@�p��e��y�����ѥ���H�{�����J�����O�̪������y��������x�C���J�������غc�P��s�w�g���۷����ɶ��A��1990�~���L���y�j�Ƕ}�l�W���i��C���J�����c�������������ǩO�H�Ĥ@�O�Y�ӻy�����Ҧ������J�C�Ъ`�N�y���ǤW�ҿסu���J�v���w�q�O�G����@�ӵ���lemma�P���qsense���W�S�t�אּ�@�ӵ��J�C�Τ��媺�Ҥl�ӻ��A��p���u��v�A�ڭ̲Ĥ@�ӷQ����O�@�Ӥu��A�藍��H�����o�Ӧr�A�o�ӵ��Ρ]��suo3�A�ۦP�����A�@�˪��r�Ρ^���ܤ֦�����Z�M�����P���N�q�G�@�ӫ��U�ؤ��P�Ϊ����ꪺ����A�p��z��F�t�@�ӬO�ꪺ�ʧ@�C�o��ӫ����O���P���N�q�C�ҥH�A�p�G�b���J�����λy���Ǥ��R���@�k�A�N�n�ܦ���ӵ��J�C���J���Ͽ�O�H�N���D�A�H�ά������C�N�q���P�A���O�_�@�Τ@�ӵ��ΡA�@�w�n������ӵ��C�N�q�Y�����A�����@�ӥH�W�i���������Ρ]�p����r�^�ɡA�h�����P�@�ӵ��J�C�Y�O�^��N�����F�A���m���A���媺�Ҥl����֡A�^�����h�CĴ�p�^�媺bank�o�ӵ��A���u�Ȧ�v�O�gbank�A���u�e���v�]�Obank�A������ɱת��ʵ��]�Obank�����������A�Ϊ̻��A��Y�ӻȦ�}�ᵥ�A�]�sbanking�Bto bank�A�ʵ��]�Obank�C�o��h�N�q�A���C�@�ӷN�q��C�@�ӧΪ��զX�N�O�@�ӵ��J�C�b���J�������Abank�o�ӵ��Φ@��17�ӵ��q�C�o�ӴN�O����¦Ѯv�����u�̸q���̻y�v�o�Ӫ��ۡA�ھڥ����N�q�A�C�ӷN�q�O�@�ӳ��A�Ӥ��]���~�����ۻP�Ϊ��Ӱ��@�ӳ��C���]�����O�@��bank�A�N�{�����O�@�ӵ��A�]�������N�q�A�N�|�⥦�Ϥ��}�ӡC�ҥH�A�C�ӻy���ү���F���Ҧ������A�N�O�Ҧ����qsense�����X�A���n�b���J���������F�X�ӡC
�@�@�A�ӳ̭��n���N�O�A�@�հ����J�y�N���Y�C�p�G�ڦA�ɥ��¦Ѯv���ܡA�Ϊ��ۡu�̪k���̤H�v�F�]�N�O�ڤ��h�y�z��������A�]���ڲ{�b�����h�i�D�A�A�����N�q�O����H�ګ��˥h���F���H���ǰ������X�G�O�L�k�w�q���C���O�ڥi�H���@�ӿ�k�i�D�A�A�o�ǵ��q����q�����A�N�q�P�N�q�����i�H���������Y�A�ӳo�����Y�O�T�w���A�������C�]�N�O���A�N�q�����ʤ��i���F���N�q�P�N�q�������Y�O�i�H���W�ߨӴy�z���C
���J�������[�c �@�@���J�����[�c���Ĥ@�ӷǫh�O�H���q����ǡA�⦳�ۦP���q���Ҧ����J��b�@�ӦP�q�����]SynSet�^�C�o��@�ӡA�P�q�����Y�O���F�ۦP�������Ҧ��������X�C�]�N�O���A���@�ӻy���]�Φ��y���^�g�L�o�˪����R�k�Ǥ���A�o�ӻy���̩Ҧ�����������z�X�ӤF�C�i��@�ӥH�W����k�Ӫ��F�Y�Ƿ����A���O����Ҧ������q�����X�C�X�Ӥ���A�o�ӻy���̩Ҧ����������w�g���F�C���F�^�媺WordNet�A�b�ڬw��EuroWordNet�]�w�g���o�t���h�F�A�{���۷�����C����ꤣ�i��u�����ƵL��A�]���y���O�ʺA�B���ͩR�O���A�����H�ɷ|���s���N�q�X�ӡA�{�����y�N�ε��J�]�i����ܡC���N�@��ϥΦӨ��A�W�z�����J�����O�۷����㪺�F�C�L�̪��P�q�����η��������j�������Q�U�ӥ��k�C �@�@�U�@�B�N�O�H�w�q�L�����J�y�N���Y�A�s���Ҧ����P�q�������C����̸q���̻y�A�w�g�ⷧ����X�ӡA��Ҧ������q��X�Ӥ���F�ĤG�B�A�Ө̪k���̤H�A���̥����ۡA�u�̷N�q�P�N�q�����@�Ӫk�����Y�k�ǥX�ӡC�ڭ̦p�G�ٰO�o�A������y�N�����ɭԡA�y�N��������N�O�A�C�Ӻ����귽�����ѥ���̡A�ݭn�G�ӪF��G�Ĥ@�N�O�o�Ӻ����귽�̭��Ҧ��������A�A�ӴN�O��Ҧ���������������z���Y�C��Ҧ���������X�ӡA��Ҧ�������z���Y�s���[�c�X�ӡA�N�O�@�ӧ��㪺���ѥ���A��Ӫ��Ѭ[�c���d��N�b�̭��F�C�ڭ̤��ҥH�D�i�n�Ωҿת��y����������Y�A�O�]���p�G�Q�ε��J�����o�˪��{���y���귽�A�N�w�g���۷��h����ơC��{���y�����F���Ҧ���������X�C�ӯS�w�����귽�ޥΪ��F�M���Ҧ������������y�N���Y��X�ӡA�K�O�إߤF�Ӻ����귽�Ҧ��������������Y�����ΡC���M�A�C�ӯS�w�귽�@�w���W�X�y���@����F�����������Y�]�Φ��@�Ǥ��b�y�������F�������^�C�����F�H�y������¦���״I��ƻP�[�c�A�ӧO���ѥ��骺�إߤ~���i��ʡC �@�@�o�̭n�`�N����J���Y�o�Ӫk�O��۷����Ѥ��e���CĴ�p�j�a���x�����ި�A�ΦP�q���嬰�ҡA�W�|��P�q���즨�@�աA������J�����A���F�P�q�B�ϸq�B��q���~�A�n���O�W��B�U��A�Υ\����Y�C�]�N�O���O�u�������ۦP�����Y�A�]���N�q�P�N�q���������Y���k�A�ä��O�u�������ۦP�Ӥw�C�����ܦh�����Y�A�o�����Y�O�ڭ̯u���b�Q�α��z���ɭԡA�Ϊ̬O�b�F�Ѫ��Ѥ��e���ɭԡA�Ҿ��Ǫ��F��C
���J�������Ѫ����Ѱ[�c �@�@�����A�j�դ@���A�ڭ̻{�����J�X�ʪ�����Synset�O���Ѫ����C�]�N�O���ڭ̥λy���Ӫ��F���Ѫ��ɭԡA�̤p���O�@�ӷ����C���O�o�Ӫ��ѳ�쪺���۬O����O�H�O�w�ӵ��J�C�����@�ӷ����A���M���O�ܮe���h���W�y�z��������A�������O����C�A��ڴy�z�������O����F��O�H�ڧQ�λy���Ӫ��F���A���O����⥦�����@�ӵ��J���ɭԡA���D���O�@�ӷ��������C�ҥH�A�o�O�γo�Ӫ��۪���찵�@���X�ʪ������A�F�쪺���ѡC�M�᪾�ѻP���Ѷ����@�����Y�A���O���l�ͥX�Ӫ��O�H�O�λy�N�����Y�Ӫ��F�X�Ӫ��C�ҥH�A�o�ӻy�N���Y�]Semantic
Relation�^�����F�����s���P���ѭl�ͪ������Y�C �@�@�ڭ̦^��@��²�檺���D�C�ڭ̲{�b���D�b�����W�A������@��j�M���n�ΡA�|���H�O�]�����O���Ӥ@�ӵ����Ϊ��h��C�ΦpGoogle�A�b������ɭԡA�O�̷Ӥj�h�ƤH�䪺���h�j�M���A�]�N�O���Ӹs�����欰�h��C�ƹ�W�ڭ̹�ϮѸ�T�����Z���x���A�p�G�O�@�ӱM�a�]��p�O�ѦҹϮ��]���^�A�b�ݤ@�Ӱ��D���ɭԡA�n�Τ����k�h��������䤣�쪺��ơH
���J�����P�����B�w �@�@�b���ں������ɭԡA���M�����C��B������ܤF�A������IJ�Ϊ���H�٬O���A�άO�@�Ӯѥ��A�@�ӹϧ��ɮסC�p�G�i�J�y�N�����ɭԡA����n�B�z���ѹB�w���d��ɡA�|�J���Ӥj���D�A�@�O���Ѧp��p�q�]How
to Itemize Knowledge?�^�F�G�O���Ѧp��s�ء]How
to Catalogue Knowledge?�^�C�ڥi�H�i�D�A�n����@���ѡA�n��@�ӹ���B�@�Ӥ��B�@��document�����@��title�C�o�O�@�ع���A�O�b���y��T���i�H�����Ʊ��A�]�����N�O�@�ӳ��C�ڳW�w���O������A�����@��metadata�����ơA���ӳo�Ӹ�ƥh��C���O�p�G�i�J�y�N�����ɭԡA�o�ǰ��]���Q���}�F�A�]�������Ī����w�q���A���n�A���Q���}�F�A�u�ѤU���Ѫ�����Ӥw�C�ڭn�䪺�F��O�@�Ӫ��ѡA���O�@�ӯS�w������C�����h�p�q���ѡH��D���Ѧ��h�֡H���h�s�ت��ѡH���諭�Ѥ����H
���J�����P�]�Ϯ��]�Ǥ����^���ި� �@�@�ҥH�A�y�L�h�@�B�^�Q�A�ڭ̭�Ӥ@���ܼ��ߪ����k�A�Ϯ��]�ǩθ�T�ɩҫإߪ��u���ި�v�C�u���ި�v���۲��I�b��ƻP�˯����G���зǤơA�]���إߦb���Oequivalence class �������W�F�û��H���O����쪺�]�����^�h�Ŭ[�c�C��ت��O�n�i�H�ܧ֧��w���]�w���T�w���O�C�]����h�W�u�аO�P�q���Y�]synonymy�^�C�p�P�ӦW���A���٬��u����v�A�]���s���A���������C���ӨB�J�h��A�]�\�i���^�夣�P����L�y���A�p�ؤ�B��嵥���C�o��@�ӥi�H�ܧ֧��w���]�w���T�w���O�A�]�i�H�B�z�����h�y���D�C�u�n�W�w���O�o�������A���M�i�H���A�ӥB��o�ܦn�C �@�@���ܦ��i��A���̭n�����@�����èS���Q�w�q�L�F�ӥB���ҷ|���ܡA�p�G�����w�q�]�ɨ�y�B�]�a��y�A�N�|�����@�ˡC�|�@�ӬO�e�@�}�l�Z��F�v�ʪ����k�A�u�f���v�N���x�W���a�H�A�~�٤H�O�u���Y�v�C�ҥH�n��o�ӦP�q�������ɭԡA�䥻�a�F����ި�i��|�i�D�q���]�n��f���A�n��~�ӤH����Ƥ]�n�䨡�Y�C�o�O�F�v�y���W���@�ӪF��C�i�O�A�p�G�A�Q�n���Ӫ��ǩO�H���Y�O���g�Ӫ��A�f���O�~�ӴӪ��F�f���O�q���w�L�a�w�Ӫ��A���Y�O���g���A���n�䪺�F�褣�O�����ۤϤF�ܡH�o�Ӥ����w�q�k�����D�A�N�O�g��y�������ۡA���O���O�H�]�����Ѫ����e��N�q�A�b���P���ɡB�a�̭����@�ˡA�ڭ̭n���˧�쪾�Ѫ�����O�H�D�λy�����i�C�����귽�A�Ҧ����F�覡�A�H�ΨϥΪ̦b�U�˯����ɭԡA�ҥΪ��i��O�P�˪����ۡ]���Ρ^�A���L�̥i����ݤ��P���ѥ���A�Φb���P���[�c�`�I�W�C�q�����ા�D�O�H���״N�b�C�Ӻ����W�A�b���Ѫ����F�W���F�i�D�A�A�ڪ����ѥ���O���˪��[�c�A�ΤF���Ƿ����C�b�Ӫ������ѥ���̭��A���M�A��ʹӪ���~�ӴӪ��B�i�Ӫ��A�O���b���P������[�c�̭��C�b�@�ӬF�v�y���̡A���S�O�@�Ӥ��P������[�c�C�u�n�Хܥ��A�N���|���W�z�����D�F�C�]���ϥΪ̤��O�]��²�檺�U�@�ӡu�f���v���˯��Υ��a���˯��Ӥw�C�L�O�b�@�ӻy�ҩ��U�A�@�Ӫ��ѽd�U�U���@���˯��C���O�e���O�A�n���o��h���ѶܡH���h�֪��Ѥ~�����O�HĴ�p�u�T���D�v��u���ͭšv�O�ۦP���F��A�b���ި��جO�ۦP���C���ϥΪ̤U�����O�O�j�M�u�T���D�v�٬O�]�x�W���^�u���ͭšv�A�����N�q�W�S���@�ˤF�C���ͭť��O�@�ӥx�W�a�Ϫ��T���D�A���@�w���S�O���N�q�p�Q�C��p���|�b�Y�@�Ӹָ̭��A�ڦp�G�g���O���ͭšA���O�T���D�A����i��O�y�z�ڦb�x�W�ͪ����g��F�Y�ڼg�T���D�A�ڥi��O�g�ڨ����ȧQ�ᨺ�h�Ȧ檺�g��A���Ӹg��W���h���O���@�˪��A���İ_�F���Ѫ��p�Q�O���@�˪��C���n���n�h��o�Ӥİ_�������p�Q�A�b�y�z�y���o�Ӫ��۵��A���b�������ɭԡA�n���n�o�ǪF��O�H�ҥH�P�q���û����P�q�A�]���b�Y�Ӫ��ѥ��餧�U�A��a���F��n���D�A��a�d��n���D�C �@�@�ĤT�Ӫ��Ҥl�N�O���b���P���y���̡A�Y�ϬO�Q�{���O�ﵥ�����J�A�����F�����������Y�ܥi���٬O���@�ˡC��责�줤�媺��l�A½Ķ���^��Otable�A�٬Odesk�O�H�b����y�����˯��ɡA�����O�O�Τ���U���A�n���l�F����˯��ɡA
table�Bdesk���n������^�ӡF�n��Ȥl�ɡA��stool�Bchair�Barmchair�Bsofa���A�������n��C�Ϊ�����sofa�A���b�o�ӻy�Ҹ̭��p�G�u�O�n���ӵΪA���Ȥl���]��p���b�����q���]�ɫ��w�n�ж�����sofa�^�C���]�Y�Ӱ��Ťj�����ж������ܵΪA���ִȤl�A���L�̥s���Oarmchair�]�]���O��H�y�^�A������H�o�ŦX�A���n�D�ܡH�Y�Ϧb�P�@�ӻy�Ҹ̡A�b��y�����ɭԡA�����@�ˡA�һy���N�q�b�o�̡A�A�y�����w�q�b���̡A�ڭ̬O���O�ల�]��ӵ��N�q�����۵��A�Ӷi��j�M�P���O�H�ڭ̪����O�b��@���J����¦�W�O���檺�A���ӫإߦb�C�ӻy���@�ɪ�������t�W�~��C��y�������ѳB�z�A�����Q�Ψ�Ӧ@�ɪ�����t�������~�ॿ�T�S���IJv�C Equivalence
Classes vs.
Relational Classes �@�@�P�˪��A���ڭ̰��@�ӹﵥ���]equivalence class�^���ܡA�W�w���O���ި�̦P�@�����ɭԡA�N�W�w���F�C�b�o�@�몺����[�c�A�@�ɤW���F�観��ءA����P�D����C����̦��H�y�M�D�H�y�A�D�H�y�����۵M���A�̭����Ӫ��B�ʪ������C�������[�c�ܦh�A�j�a���ܼ��x�F�A�]�`�`�o�{�b���R�ɡA���ǪF��N�O���̤]�ᤣ�i�h�F�Ϊ̻��b���P���y�Ҹ̭��A���|�����P���N�q�A�ӥB�ݩP���X�����C�t�~�A���ɭԤ@�շ����Ψƪ����P�˪��欰�Τ��G�A�S���G�ӭq���@���CĴ�p�U���B�����B���s�A�U���B�����B���s����H�O����H���̦b�ڭ̪������̭��A�b�ڭ̤�`�ͬ��y���ϥΪ��g��̭��A���O�@�����C�o���F�賣�O�i�H�U���B�����B���s���C���ެ�ަp��i�B�ACD���N�F�������A�N�Ӧ��s���������NCD�A�o�@���ƪ����������|�]�ӧ��ܡC�����M�]�A�Ʀ��ɮסB�q�l�ɡB��Ū�ɡB�{���C���O�i���i�H�U�����֩O�H�i���i�H�U���ۤ��O�H�i���i�H���s�p���O�H���M�i�H�C�b���@�ӯ��ި�̭��|�i�D�A���O�P�@���H�S���a�I���N���J�F�C�]���A�o�˩Ҧ����F�賣�O�P�@���C�i���i�H�U�����h��O�H�i���i�H���������O�H�i���i�H���sStephen King�O�H���M�i�H�ڡI�ҥH���ͤ@�Ӱ��D�F�A���j�������ި�̪�equivalence classes�A�w�q�T�w�@�������F��A�b��ڨϥήɳ��Q���}�F�C�y���̭����ͪ��@�Ӧ]���ƥ����Y�өw�q�����A�b�����̭��ϥΪ��ɭԡA�����O�P�@���A�ä��ݭn�t�~�h�y�z���O�P�@���C�]���A�����O�@�Ӧ����Ѥ��e�]content�^���F��C�]���A�b�U�����֪��ɭԡA�ﭵ�֤��O�@�ө�H�������A�O�U���Y�@�q��ڪ����֡A�O�U���Y�@�Ӭۤ��A�O�U�����h�⪺�Y�@�@�~�A�@�ӥ��T���A���O�U�����h��o�ӤH�C���ګ�D���O�U�����h��o�ӤH�O�H�]���A�ڪ��D�ڤU������H�C�o�̦��@�����Y�s�b�A�o�Ӱʧ@�Ұw�諸���Y�A�O�۵M���B�����e�����C�ҥH�A���˱q���۱o�쥻��H�y���O�Ӫ��ۡA���������۬O�]���ܦh���ѥ��餤�����P���Y��{�X�ӤF�A�~�����o�˪��C�ڭ̱`�ϥΪ��@�ӨҤl�A�ѡB�ѥ��A�o���F��̦n���F�A�A���ѥ��o�Ӥ峹�ܦ���A�O�����e�F�����ܪ��A�T�U�h�r�A���O���e�A�O�Τ�r�Ӫ��F�F�o�ѬO��⪺�A��⪺�O�������~�[�F�o�ӮѬO��˪��A�O�������˭q�覡�F�o���Ѫ�F�ڤQ�~���ɶ��A�O���ڼg�@���L�{�C�аݮѬO�@�ӷ����A�٬O�H�W�Ҵ����X�ӷ����H���ѬO�@�ӥ���A���ۤW���p�G�n�h���A���N�O�@�өΦh�ӡC�ҥH�A���ɭԤ��n�g��ۡA���ɭԤ��n�g����A�]���ھڧA���z�סA���A��誺�w�q�A�ܥi�����A���L���Ӭ۬O�@�P���o�Өƹ�C�]���ѴN�O�o��@�ӪF��A���O�o��h�����զX�A�]���Ѫ��w�q��ڭ̪����ѤW�A�N�O�����e�B����r�B���L��覡�����������C���O�@���q�l�Ѫ��ɫJ�A���N�O�S���ȤF�A���N�O�@�ӹq�l�ɮסA���O���O���O���h�F�Ѫ�����O�H��ڭ̨����A��ϥλy�����H�ӻ��A��������O�s�b���A���٬O�ѡC�ҥH�A�b�o�ӻy���̡A�ڭ̧�o�@�շ��������X�ݦ��@�ӳ��C�q�H�P�y���ϥΪ��[�I�X�o�A���ڭ̪��D�o�Ǧb�Y�Ӫ��Ѥ����W�����A�]�Ӧ��G�����Ϥ����F��A�b�ڭ̪����Ѭ[�c�����X���F�@�ӳ�@���������C�O�y���i�D�ڪ��A�O���ۧi�D�ڡA�����O�@�շ����A�Ӥ��O�@�s���}�����P�����A���S�O����A�S�O�q�l�ɮסA�S�O�奻�����������C�������A���ڴ���i�H�U���B�����B���s���@�ըƪ��A�ھڧڭ̪��y���ϥλP�g��A�i�H�w���j���]�i�H�\Ū�B�Y��B�R�������C�o�˪��ƥ�欰�P�g��A�S�b���Ѭ[�c�W���ͤF�@�ӷs�������s�աC�i�H�o�˲��ͪ������G�L�a�C���O�A�b���ѥ���W�A��꦳��²�䪺�B�z��k�C�]�N�O���A�o�Ǩƥ�]event�^�������O�����B�L�i�קK���C���]�ѻP�ƥ�ۦP�Ӹs�E���ƪ��A�h�����t�ߤ@���C�L�̥i�ǵ۰ѻP�ƥ����Y�ӳQ�w�q�C�]�N�O���A�L�̪��������Y�A�O�b�ѻP�P�@���ƥ���U���ͪ��A�Ӥ��O�����W�����M�C�责��̭��n���O�A�b���J�����̭��A�ڭ̩Ҭݨ쪺�A���u�O�P�q�P�ϸq�����Y�A�ܭ��n���O�@�Ǩƥ����Y�ʪ��F������N�O�o�ӡC�ƥ����Y���w�q�A�Ϫ��ѥ���W���������Y²��ơC
���q���Y �@ �@���J�������S��A�]�O�̭��n���зǡA�O�b�C�ӦP�q�����]�Y�����^�W�аO�@�ոg�L�Y�ԩw�q�����q���Y�C�o�ǵ��q���Y���s���A�c���F�H���J���`�I�������C�H�U���C�|�y�N�Dzz�פ��̨嫬���E�ص��q���Y�A�Ψ�зǤ�Ķ�A�å[�W�D�嫬���諭�Ѫ��x�D�`���n���A�J�]Involved�^���Y�[�H�����G
antonymy
�ϸq���Y hypernymy
�W�����Y hyponymy
�U�����Y holonymy
���������Y meronymy
����������Y metonymy
������Y near-synonymy
��q���Y synonymy
�P�q���Y troponymy
�覡���Y
�P�q���ϸq���YSynonymy/Antonymy
�@�@�P�q���ϸq���Y�C�ϸq���A�P�q���C�P�q�����M�j�a�w�۷����x�A���t�h���C�ϸq���b�y�N���Y�W���a��A�ˬO�ȱo�Q�סC�@��H�q�`�H���ϸq���O�N�q�ۮt�Z���̻�����ӵ��C���A�q�y���Ǫ��[�I�����A�ϸq���O�y�N�Z���̪�ӵ��C���Ӥ��A�q�`�P�̿˱K���H�n�[�O�̿E�P���F��p�ڰǴ��Z�M�H��C���o�A���ڬ��A�L�̦P�O�{�ڤH�]Semite�^�A���ڦ�t���O�̪C�@�P���ͬ����һP�귽�ݨD�y���Q�q���v���P�Ĭ�F�b�ݨD�ۦP��y���v���A�S�ʤW�ǷL�����P�K�y����ߡC�b���y���A�ϸq���ھڻy�N�Ǫ��w�q�O�A��ӵ����F��y�N�S�x�~�A��L�Ҧ��y�N�S�x�����@�ˡC�]�N�O���A�ϸq�����\��O�b�Y�ӷ������Y�W�����A�ӭn�إ߳o�ӹ��A��L�]�y�N�^�����ۦP�C�t�@�ӻ��k�A��o�����Y�]�\�����U���A�N�O�ڭ̱`�����uī�G�����l��H�v�ϸq�����A�O�إߦb��L�y�N�S��ۦP������W�C
�@�@�H�U�H�X�ӨҤl�����Q�סC��p�R���O�@��ϸq���A�Ҳo�A���ʧ@�@�ˡA�u�O��V���@�˦Ӥw�C�D�P�G�A���魫�A�@���魫���ƶq�j�A�@�Ӽƶq�p�A�u���@�ӯS�褣�@�ˡC�ҥH�A�q�[�������A��p�q�j�M�A�Ψ�L�q���Ѫ��B�z�����A�|���|�Q��Τϸq���h�j�M�A�O���\�����䤧�@�C���]���A�n��u���v���F��A�A�|�Q���F�����ھکw�q�O�ϸq���A�]�����u�O�y�z�C�⪺���Ф��@�˦Ӥw�C�]���A���A�h�j�M�����ɭԡA�H�O�|���ɭԤ@�ӵ��Q���X�ӡA�@�ӷ����Q���X�ӡA�|�������������A�|�Τϸq���C�p������A�䤣��A�|��B�B�B�Χ䫿�l�A�o�˪����Y�ϸq���C���O�A�q�`���j�M�����̬O���|���ѳo�˪��\��A�]�����~�{���ϸq���N���ۧ������P�������A�����F�ϸq���~�O���q�Z���̪C�o�O�@�Ӥϸq���������C
�W�����Y���U�����YHypernymy/Hyponymy
�@�@��W�����Y�����s�u�W����v�A�S�٤@�x�ٵ��C�p���T���O�@�إ�q�u��]vehicle�^�A�o�K�O�@�ӤW�����Y�C�W�����Y�P�U�����Y�]�Yis
a kind of�����Y�^�������ʡA�O�����X�{���C�o�����Y���ɭԬO�����ʪ��A�p�N�����O�@�بT���A���M�]�O�@�إ�q�u��C���O���ɭԬO�D�����ʪ��F�p��ЬO�v�Ъ��@�ءA�I�v�S�O��Ъ��@�ءA�����I�v�O���O�v�Ъ��@�ةO�H�b�j������������t�̡A�I�v�B�ѥx�v���O��Ъ��@�өv���A���o�өv�����q���[���O�u�����Ъ��A�]������W�ǡC�ҥH�A�Q�פW��B�U�쪺���Y�A���ɭ��٬O�n�Ҽ{���Y�������S�ʡC�]�N�O���A���q���Y���ɩw�A�ä��O�u���@�����Y�s�b�P�_�����¡C�]���A�ڭ̦��ɭԷ|��@�����Y����ԲӪ������A���H�U���Ъ�����w�������Y�C
���������YHolonymy
�@�@�^���診�@�Ӱ��D�A���@�ӱM�a�A�h�M��@�ӷ����B�@�˨ƪ����ɭԡA�N��A�ۤv�Q�F��Q���X�Ӫ��ɭԡA�s���X�W�r���ɭԡA�|�Τ����k�h�ѨM���D�A�G��n�䪺��H�H�ƹ�W�N�O�a�y�N���Y�CĴ�p�A�i��n��@�Ӫ��A�@�ɪ������X�ӡA�A���Фl�]������A�]���O�Фl���@�����^�A������]�ϸq���^�F�Q�Τ��P���y�N���Y�����A�Q�n�h���ӵ��A���@�w�O�ΦP�q���A���@�w�O�ΦP�����C�H�̳̱`�Ψ쪺���q���Y���@�N�O�����w�������Y�C�ж������A�⦳����Y�A�r�����e�A�o�dz��O�����w�������Y�C �@�@�ڭ̭责�쳡���w�������Y�A�i�H����Ӫ������CĴ�p�����զ�����HAS_HOLO_PART�BHAS_MERO_PART�A�M�������O�i����C�Ҧp�G��}���l�A�i�H�@���@���Q��X�Ӫ��C�ĤG�ӬO���X���]SET-MEMBER�^�����Y�A�Ҧp�G���F���O���ժ��@�����A�y���O�y�����@�����F�L�̳��O�@�Ӷ��X�̭����@�����C�ĤT�ӬO����P�զ������]PORTION�^�������Y�A�p���P���ɡA�e�y�����v�P���w�C�զ������A�b�^��`�O�@�Ӥ��i�ƦW���C�U�@�ӬO�����w�������Y�o�A����ơC�Ҧp�G�ȱi�P���y�A�o�Ӥ]�O�C�զ������P���Ƥ��P���a��b��զ������i�H�Ѿ�����Φ^�_�]���i�H�����L�Ƥp���w�^�F���ƵL�k���Φ^�_�]�Ѥ���A�ܦ^�ȡ^�C�b�a�z�ϰ�W�]�������w�������Y�A��p��w�O�F�z���@�����C�b�����W�����A�o�O�`�Ϊ��Ҥl�C���h�w�q�@�Ӻ�w�A�Ӥ��w�q�F�z�O�H����������a��N�s��w�A�������a��n�b�F�z�̭��~�s��w�C�ҥH�A�o�ӵ��q���Y�w�ܦ��F���q���w�q�C
�@�@�ڭ̤��ҥH�|���o�����Y�A�O�]���ڭ̦^���责�쪺�A�N�O�o�DzӤ������Y�U�����P������z���Y�C�b�����w�������Y����¦�W�A���ǡ]�y�N�^�S�ʬO�i�H�~�Ӫ��C��p����l�O���Y���A����i�H�_�w��}�]�O���Y���F�p�G��l�O��Ϊ��A�o�����_�w��}�]�O��Ϊ��C�ҥH�A���P�������w�������Y�|�v�T���P�������~�ӻP����z�C�o�a�X�F���q���Y���мm���t�@�ӭ��n���ѳB�z�\��A�N�O�w�q�U�إi������~�ӻP����z�C�A�H�զ��������Y���ҡG�Y�����ܦn�Y�A���ɷ��M�]�ܦn�Y�F�����o�J���N�o���P�A�o�����_�w���ɫ��P�a�I��ӨS���Q�o�ӨƱ����e�A�|�{����w�@�w�s�b�F�z���o�Ƿ����ݩ�`�ѡ]real
world knowledge�^�C�ƹ�W�L�̦b�C�ӤH�����J���Ѹ̽T��s�b�A�������J�O�y�����ѥ��骺�Q�k�C
������YMetonymy
�@�@������Y�A�o�O�b�{�N�y���̱`�Ϊ��CĴ�p�u���]Cisco�^�ŧG�����v�A�o�Ӥ��q�A���O�@�ӵL�ͩR���F��A�|�ť��ܡH���O���Y�ӵo���H�ť����A�Ϊ̬O�H�ڭӤH�g��Ө��A���u�x�_�D��COLING2002�v�A�x�_�o�ӫ����|�D��ܡH���M�O���x�_�̭����Y�Ӧ����ӿ�o�Ӭ�Q�|�C�Τ@�Ӳ�´���k�H���a�ϵ����W�٨ӥN����ڰ���u�@���@�ӤH�A�o�N�O������Y�C���ɭԥΤj�N�p�A���ɭԥΤp�N�j�A�O�ڭ̱`�Ϊ��@�ӻy���W���F��A�������ۦp���C���B�z���ѮɡA�ڭ̥������D�u�����ͳo�����Y�A�u�����o�Ӱʧ@���O�֡H �覡���YTroponymy �@�@�覡���Y�A�D�n�O�Φb�ʵ��W�C�b�������z�̭��A�O�⥦�����W�B�U��A���O�W�{�b���⥦�٬��u�覡���Y�v�C�p�b���~���A��l�O�@�سíѡA�O�@�ؤW�B�U�����Y�C���p�ΡB���B���B�L�U�O�@�صN�����ʧ@�A�o�ɭԥ��P�W�U�����Y���@�˪��a��b���̩O�H�b�y�N�P���������̡A���D�n�O�覡���@�ˡCĴ�p����move�A���ʪ��覡�������B�]�B�C�]�����C�Ҧ��o�ǰʵ����ʪ��ƥ�O�@�˪��A�u�O�ƥ�i�檺�覡���@�ˡC�o���O�����~���������Y�A�ӬO��Y�@�ئ欰�b�覡�]manner�^�W����ӷL���Ϥ��C�����W���t���A�i��b��t�סA�i��O�u��]�p��^�\�ʪ��T�����������C����A�ΡB���B���B�L�i��O�ϥΪ��u�㤣�@�ˡA�����ūפ��@�ˡA�o�O�ƥ�g�窺�@�����C�b�y�����F�W�A�N��P�����ƥ�A�Τ覡�Ϥ��C
�A�J�]Involved�^ �@�@���L���y���y�N�����A�̦����]�p���õL�A�J���Y�F�D�n��]���@�O�]���L���]�p�⤣�P�����������}�B�z�A�ä����\��������y�N���Y�C���O�A�H�������Ѩt�Τ��èS���o�˪�����C��p���A�ƥ�P�ѻP�̡��A�J�̪��������Y�A�ä��]���L�̤@�ӥΰʵ��A�@�ӥΦW�����F�A�ӱq���ѥ��餤�����C�n���A���ڭ̦Ҽ{��ƥ�P�ƪ��o�������骺�t�ΡA���ܦh�O�n�a�A�J�����Y�ӳs���A�ӹ�{����z�P�����~�Ӫ��C�]���b���߶}�l���ڻy�������N�[�J�F�A�J���Y�C�ڭ̤]�Ĩ��o�Ӹ��s���[�c�C �@�@�A�J����A���A�J�I�ƪ̡B�A�J�g���̵��CĴ�p�p�l��i�աB�����C�ڷQ�ӤH�|���o�˸g��A�A�Q���j�p�A�j�p�o�ӦW���Q���X�ӡA�A�|���N���]���H�^�C�o�Өƥ�O�@������]�ΤH���^���y�N���Y�A�b�y���̩M�b���ѥ���̭������ܭ��n���a��C�o�����Y�O�g�Ѧp��h�w�q�@�Ӽp�v�ӫإߪ��A�]���y���̩w�q�p�v�O�N���B�i�����H�C���b�Dzλy�N�[�c�̭����Ӫ��F�o�����Y�A�o�O�ڭ̤���ݭn�b���J�������[�i�Ӫ��C�t�~�A�ϥΤ���u��]�O�ܭ��n���A�J���Y�CĴ�p�ڭ̬����p�a�O�H�p�O�@�Ӥu��A�b�p�a���ƥA�p�o�Ӥu��O����۪������S�x�A�y���W���ڭ̳o�˪��ҾڤF�C �@�@�A�J���u��A�����ҡB�ʦV�K�K���A�N���@�@�C�|�F�C���J�����Ψ쪺��L�A�J����A�i�Ѩ�EWN�����W�Ρu�y���y�Сv�����W���m�������C
���J�����]WordNet�^�����귽�{�p �@�@1990�~���L���y�]Princeton�^�}�l�i�氵���^�y�����]http://www.cogsci.princeton.edu/~wn/�^�O���J���������ҡC�ثe�w�g�O1.7���F�A�i�H�W���h�˯��C�o�O�^�y��y�C�t�~�A�ڻy�����]EuroWorNet�AEWN�^�O�b1996�~�}�l�����]http://www.hum.uva.nl/~ewn/�^�C�ڷ��N�Ѩ�p�G�n�h�B�z���Ѫ��ܡA�����n�Ψ���J�����W�o�˪��[�c�C�M�ӡA��ڸ�T�ɪ��D�n��s���c�A�ѩ�O���~�]�pIBM�AAT��T�AMicrosoft�^�Ҥ���A�j�����M�Ѧ��Q�i�Ϫ��^��C�M�ӡA���ڬw���v���O�۷Q�A�S����S���ڬw�U�y�������J�����귽�C�ҥH�A�ڷ���´�W���øɧU�F�h�ؼڬw�y���������غc�C�ӥB��h�y����ƳB�z����������U��A�N�]�O�@�P�}�o�C���M�A�P�^�y���s�����i�֡C�ҥH�A�ڻy�����P���L���y���^�y���J�����O�ۮe���C�ڻy�����]�A���ڴ��J�y�]Basque�^�B�d�F���y�]Catalan�^�B���J�y�]Czech�^�B���y�]Dutch�^�B�k�y�]French�^�B�^�y�]English�^�B�R�F���Ȼy�]Estonian�^�B�w�y�]German�^�B�q�j�Q�y�]Italian�^�B��Z���y�]Spanish�^�B���y�]Swedish�^�B���»y�]Norway�^�B�����y�]Danish�^�B��þ�y�]Greek�^�B������y�]Portuguese�^�Bù�����Ȼy�]Romanian�^�B�߳��{�y�]Lithuan�^�B�Xù���y�]Russian�^�B�O�[�Q�Ȼy�]Bulgarian�^�B�����奧�Ȼy�]Slovene�^�����C��Ӽڬw�y���j���������J�����w�g���n�F�C�]���A�ڭ̥i�H�o�˻��G���y���j���������J�����w�g���n�F�C
�@�@�b����譱�A�]�w���F�@���������J�������귽�A�s���u�����v�]HowNet. http://www.keenage.com�^�C�Ѥj���������F���ͦb1995�~�ۤO�ۤ�i��C���O���^���^�����@�����y���J�����C�������O�}�Φ��O���C2002�_�s����Ѥ����ǰ|�n��Һz��A�N�ݭn�I�O�ϥΤF�C �@�@�u�����v�@�k���S��O�W��@�m�F���ĥέ^����J�������[�c�A�u�n�Ĩ��L�ۤv���[�c�C�ӥB�L����@�ɪ��ѥ��鰵�өw�q�A�b�o�w�q�̦A�h���Ϥ��C�o�ӥѤW�ӤU����k�A�P�^�y�P�ڻy���J�����ѤU�ӤW����k���P�A���M����i�����B�C�i�����O�A�ѩ���~�귽�P�T��������A�����F�б»P�L����l���j�A�W�O�̵۫H���P���ۧ����u�����v���A�L�{�����֥~�ɪ������A�]�å��P�@�ɬ�����s���y�C�L��L��l��F�����C�B�K�~���\�ҨӰ��o�ӨơC���O�A�W���L�y�������J�����s���A�õL�[�c�W����¦�A�Ө�W�h���Ѥ����A�]�O��H���ۥѤ��ҡA������A�o�]�ʥF�z�ת���¦�A���{�@�ǻP��L�t�Τ��q�ʡ]inter-operability�^�����D�C �@�@�]���A�{�b������s�|�b2000�~�}�l���A���k�O�����^�������y���J�����C�e�������i���^�媺���J������ڻy�����J�����L���y���J�������X�_�ӡA�j�����Q�U�ӷ��������A�ڭ̧�Q�U�ӷ����������@�ӭӪ��ݡA��X�̦n�]���U�������F�P�y���ϥΡ^������½Ķ�C�o�ӧ�X�̦n������½Ķ�A�̭��n���@�I�O���y��Ķ�����o�i����Ӫ��F���������ۦP�����C��~�����o�Ҥl�Gtable��desk�o��ӭ^�y�A�i��̪�����½Ķ�N�O��l�C���ƹ�W�����O�@�ӦP�q���C��l�Odesk���W����A�]����l�]�A�Fdesk��table�o�����C�ҥH�A�n��½Ķ���ɭԬO���W�U�쵥�����Y�A�����n��y�N�����Y���F�X�ӡC�S�porange½Ķ����l�A����l���u�Oorange�A�^�y���٦�tangerine�����������O��l�C�ڭ̤����l���O�n��½Ķ�A�o�]�����l�b���������Ѥ��e�W���P��orange�C�����@�����y�������ഫ�ɡA�����n���D��Ķ�������y�N���Y�C�ҥH�A�ڭ̧�Q�U��WordNet�������X�ӡA�{�b���b�аO�A��y�N���Y�إ߰_�ӡC�]�N�O���A�ڭ̧����y���������Y�A�����y�N���Y�B�z�C������ƥi�Ѩ��ڭ̪����}http://corpus.ling.sinica.edu.tw/ project/LanguageArchive�C
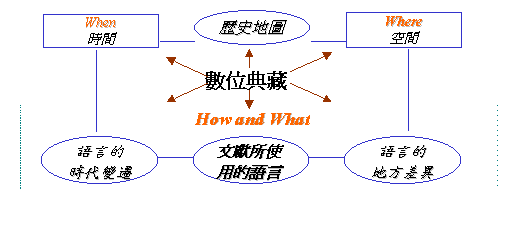
�y���y�Тw�w�ѦҸ귽�ظm�P�A�ȷ����� ���y�G�w��ѥ[�u�y���y�Сv���ظm�u�@
�@�@�H�W���ϬO�u�y���y�Сv�o�ӭp���������P���Y�ϡC�o�g�峹���ͨ쪺��s�A�N�b�u�y���y�Сv�p������{�C�o�ӭp���O�b�¦Ѯv�t�d���u�Ʀ���ð�a����ޭp���v�����@�Ӥ���p���C���Q�k�O�A�Ʀ���å]ù�U�H�F���O�n�h�������ä��e���Ѫ��ɭԡA�o�@�w�n���D��l���ê��y���C���A�ɪ��ܾE���|�v�T���e�������C�]���A�ڭ̥����b�ɶ��B�Ŷ��W���A�ھڻy���Ӱ��@�Ӽ��ѡA�w��Y�ӥD�D�B�Y�ӻ��ϥΥ������e�O����C�o�N�O�y���y�СC �@�@�y���y�ЬO�n�y�z������ä��e��how�Pwhat�A�]���n���D���ѬO���Ӫ��F�û��H�ɪŪ�when�Pwhere�A�y���y�Ш�U���ä��e���Ѫ���g�P��Ū�C�w��C�ӮɥN�B�C�ӥD�D�B�C�Ө��áA���ؤ��P�����J�w�A�b���P�����J�w�W�ؤ��P�����J�����A�o�N�OOntology����¦�C�N�O�b�y�N���������ӵo�i���A�Ʀ���å����n�g���ѥ���]Ontology�^���C���~�ର��ҥΡC�y���y�д��ѤF�Ѩ��ä�������骾�ѡA�H�Φb���P���ѥ��餤�إ߷����ഫ�����n��¦�[�c�C�p�G�C�C�ذ_�ӤF�A�]�N�O�b�إߨ��ê��L�{�A�]�إߤF���㪺���Ѭ[�c�C�o�N�O�@�ӯE�j�����Ѥu�{�A�ݭn�j�a�@�����|�I
��O �@�@�y���y�Ъ��u���P���ѥ������y�˯����������v��b2002�~�������Ghttp://ckip.iis.sinica.edu.tw/CKIP/ ontology/�A���F�i�H�˯����^��Ķ�~�A��i�H�˯�SUMO�q�ΤW�h���ѥ���A�^�y���������q���Y�A�γ������аO�C�ϥΪ̭Y��^�X�s�����аO�A�Ψ�L��ơA�ñN��§�~���ءA�w��ϥΡC
�i�s�̫��j���嬰�����ýZ�A�g���̼����f�\�Z���C