佛教圖書館館訊 第十八/十九期 88年 9月
大藏經電子化的實作:
以大正新脩大藏經為例
中華電子佛典協會 釋惠敏
一、中華電子佛典協會簡介
 中華電子佛典協會(Chinese Buddhism Electronic Text Association,簡稱CBETA)是聚集一群專職的人才,運用現代化的電腦、通訊、資訊科技的協助,將各類型的佛學文獻資料加以數位化,並透過有效的資訊管理,提供即時、即地的服務,正確而快速有效的滿足使用者對佛學資訊的需求所成立的團體。目前則致力於在三至五年內完成大正藏第一冊至五十五冊及第八十五冊的電子佛典,免費提供大眾使用。
中華電子佛典協會(Chinese Buddhism Electronic Text Association,簡稱CBETA)是聚集一群專職的人才,運用現代化的電腦、通訊、資訊科技的協助,將各類型的佛學文獻資料加以數位化,並透過有效的資訊管理,提供即時、即地的服務,正確而快速有效的滿足使用者對佛學資訊的需求所成立的團體。目前則致力於在三至五年內完成大正藏第一冊至五十五冊及第八十五冊的電子佛典,免費提供大眾使用。
(一)本會宗旨
1. 研發佛典電子化技術,提昇佛典交流與應用。
2. 利用電子媒體之特性,以利佛典保存與流通。
3. 期望讓任何想要閱藏的人都有機會如願以償。
(二)成立緣起
過去數年間,經由許多朋友們的共同努力,在網路上集結了不少佛教經典,也因此帶動一股佛典電子檔輸入熱潮。大家的目標主要是著重在網路應用,比如將這些電子檔置放於FTP上供人免費下傳,或是透過GOPHER、WWW方便使用者瀏覽,最近更在WWW上提供檢索查詢功能。此外,另一個發展方向則是將電子檔包裝設計成電子書,利用電子媒體的強大介面以使經文的呈現更加精緻。而這些努力,無非希望能夠透過網路,使佛典普及,讓更多人同霑法益,並利用電腦的能力,拓展佛典的應用範圍及改善閱讀方式。
而後,因蕭鎮國先生來函,慷慨地提供25冊CCCII大正藏電子稿,並於1997年11月6日25T小組籌備會議之後,授權台大佛研中心進行後續之處理。網路上電子佛典討論版(buda-tech)的朋友們便草擬了一項電子版大藏經輸入計畫,開始有計畫的進行經典輸入。1997年11月6日正式由台大佛研中心成立25T小組,著手開始進行大規模的藏經電子化。
(三)正式成立
由台大佛研中心恆清法師開始籌募所需經費,獲「北美印順導師基金會」與「中華佛學研究所」全力支持贊助後,得於1998年2月15日假法鼓山安和分院舉辦籌備會議,並於當日正式成立「中華電子佛典協會」。
(四)助緣
除了上述緣起之外,中華電子佛典協會的成立,亦感謝許多朋友的鼎力協助以及各界的關心,才能使本會佛典電子化的工作,得以順利的推展。
1. Buda-Tech討論群:台大獅子吼BBS站及中山鹿苑佛教BBS專站的討論版,專門進行佛典電子化的相關
問題討論,並由曾國豐先生架設MailingList提供討論者使用。許多佛典資料及相關技術都是本版網
友努友的結果。
2. 電子佛典編輯小組(EBTWG):由徐言輝及幾位朋友組成之小組,主要是利用SCAN+OCR技術,以佛教
大藏經為主,而有系統的產生電子經文檔。
3. 25T小組:由台大佛研中心主導,負責處理蕭鎮國先生所提供之25冊CCCII格式的大正藏經文檔,本
小組即為中華電子佛典協會之前身。
4. 缺字小組:為了深入討論佛典缺字的解決方案,而另外成立的討論小組。
5. 其他。
(五)本會目標
1. 初期以完成大正藏1-55、85冊電子化為目標。
2. 完成極低錯誤率之高品質電子經文。
3. 提出電腦缺字之有效處理方案。
4. 利用電腦技術,以整合不同版本藏經校勘之查閱。
5. 整合全文檢索之工具,以提昇電子佛典之應用。
6. 利用網路特性,將漢文佛典呈現至世界各處。
7. 開發單機版之使用介面,以利大眾使用。
(六)本會組織簡介
中華電子佛典協會
│
委員會─常務委員─主任委員─執行顧問─顧問團
┌─┴─┐
副主委 副主委
└─┬─┘
總幹事
┌─┬─┬─┼─┬─┬─┬─┐
研 資 缺 輸 校 網 發 財
發 訊 字 入 對 路 行 務
組 組 組 組 組 組 組 組
1. 顧問團:由諸山長老及學術單位所組成
2. 委員會:本協會以委員會方式組成
3. 常務委員:代表委員會監督協會事務之進行
4. 主任委員:委員會設置主任委員一名,負責整體事宜
5. 副主委:主任委員下設副主委二名,以協助主任委員
6. 總幹事:協調各組工作及對外行政事宜
7. 研發組:負責提出前瞻性、國際性及學術性之整體規劃
8. 資訊組:負責技術程式以及網路、單機應用程式之開發
9. 缺字組:負責電腦上之缺字處理
10. 輸入組:負責經典輸入之進度及規劃
11. 校對組:負責成品之電腦比對及人工校對事宜
12. 網路組:負責將各組工作之近況及成果利用網路呈現
13. 發行組:負責電子佛典之推廣及成品發行之事宜
14. 財務組:負責總管財務之運用
15. 研究助理:聘請學生擔任
16. 義工:特別感謝許許多多發心幫忙的義工,無論在校對業務或是行政事務上,亦或是經文輸入及資
訊技術的提供,義工朋友們均不求回饋地給予我們支持,在此獻上最崇高的敬意與謝意。
 (七)成果
(七)成果
本會於去年12月25日假慧日講堂舉行「中華電子佛典協會年度成果展」,會中除提供測試版電子佛典CD予與會貴賓外,亦獲得大家的支持與指導。測試版的電子佛典包括大正藏第五冊至第十冊的普及版經文,以及讀經器和相關工具(如佛學辭典、文字檢索工具等),亦同時上網供大眾下載使用。
本會發展之工具和流程,亦公開提供與大眾使用,您可至我們的網站,取得最新的訊息和技術。
二、中華電子佛典協會作業流程簡介
中華電子佛典協會成立至今已逾一年,感謝許多朋友不吝指導協助。一年來我們也漸漸的將佛典電子化的流程逐一確立,希望在將來能夠更順利的產出佛典,提供大家使用。
中華電子佛典協會並非屬於一個人或是少數人便能夠支持,在我們成長的過程中,若沒有許多朋友的鼎力協助,相信是無法達到現有的狀況,也企盼將來仍能持續地得到大家的支持與鼓勵。
本會處理經文的方式,主要是採用不同來源兩個以上版本的經文電子檔,利用程式進行比對,再利用看圖校對的方式產生一較正確的經文電子檔,再交由人工校對。這樣的處理方式,在速度及品質上均令人滿意,尤其是若干經文檔本身的品質不甚理想,常在直接交付給義工菩薩進行校對時,造成很大的困擾。為了秉持高品質的原則,因此我們不會將未經過看圖校對的經文流出,藉此對許多來函索取經文的朋友們致歉。
作業流程示意圖
資料輸入及比對經文搜集
↓
缺字及格式整理
↓
檔案比對
↓
看圖校對
↓
人工校對
↓
標記處理
↓
電子檔上網
↓
全文檢索等應用
↓
使用者之建議與指導
↓
修正並更新
(一)資料輸入
對於大量的佛典經文的輸入,我們針對不同的內容,選擇採用打字輸入或是掃描圖檔辨識的方法來產生文字檔。
OCR所使用的程式,要感謝力新公司的鼎力協助,並針對我們特殊的需求,開發了丹青for CBETA版本,特此誌謝。由於力新公司的幫忙,使得我們在處理大正藏經文時,能夠取得一個較好的解決方案。
OCR的流程簡述如下:
經文圖檔掃描→去除雜點→OCR→學習詞庫及後處理→線上校對→經文
(二)比對經文搜集
除利用原本網路上許多大德所輸入的經典(如佛教經典系列)之外,也感謝許多出版社及相關單位慷慨提供經文電子檔,讓我們能夠順利的作業。
另外,我們也尋求各式各樣的合作機會,無論是針對國際佛典電子化的伙伴,或是學術研究機構、出版團體等等,均能在互利的情況下,相互支持。
針對各界提供我們的經文,如果有需要,我們會在校對完成之後,提供一份校對報告,讓出版團體能夠針對我們發現的問題進行檢查更正。
(三)缺字及格式處理
佛經中大量的缺字,是處理經文所面臨的第一個大難題,目前解決的方案有許多種,本會為了顧及各方面的需求,嘗試建立相關的資料庫,能夠提供不同方案之間的轉換。如代碼取代、造字轉換等。
此外,不同版本和來源的經文,在排版、標點、校勘等等可能有很大的差異。因此,得預先進行初步的格式處理,以利比對作業。
(四)檔案比對
利用檔案比對程式進行經文檔案比對,產生差異檔,在進行差異分析之後,針對高頻次差異進行取代處理。
(五)看圖校對
利用先前掃描之圖檔和經文比對差異檔,及看圖校對程式,進行線上看圖校對。原則上採取兩組同時進行,再將結果進行交叉比對的方式。
看圖校對後,亦進行後處理做進一步的檢查,及原版藏經的查證工作。
(六)人工校對
將看圖校對後決定的經文,列印提供義工進行書面校對。在此感謝所有參與書面校對的義工菩薩們。如果您對參與書面校對工作有興趣,歡迎和我們連絡。
書面校對後進行訂正,接著進行標記的處理。
(七)標記處理
標記處理分成兩部分,先進行簡單標記的處理,再利用程式轉換,進行細部的標記處理。
(八)電子檔上網
利用標記完成之經文檔案,產生普及版之經文檔,上網提供大眾使用。
 (九)全文檢索等應用
(九)全文檢索等應用
針對不同的使用需求,發展工具提供大家利用,以擴展電子佛典之應用性與價值。(見右圖)
(十)學術性應用
由研發組主導開發相關之學術應用程式等。
(十一)使用者之建議與指導
接受來自世界各地使用者之指導與建議,並不定期針對使用者的意見,召開組際會議,進行討論。
(十二)修正並更新
依使用者的建議和會議的決議,對經文內容或是相關工具,甚至是處理流程進行修正和更新。
三、結語
經過了一年來的嘗試與摸索,我們建立了一套順暢的流程,感謝每一位同仁在打通每一道關節上付出的心血和努力。當然,我們也將本著精益求精的精神繼續努力。如果您對於我們的作業流程有興趣,或是有任何的建議,歡迎和我們連絡。
【研討報告】
編者按:本文為惠敏法師於「佛教資料電子化研討會」上發表的報告,由本刊編輯組謄稿整理。
主持人、主辦單位、各位來賓,今天這個主題大概分成二個部分來說明。首先談數位化的文獻與多價文獻模式(Multivalent Document Model)的關連性,再談中華電子佛典協會(Chinese Buddhism Electronic Text Association,簡稱CBETA)大藏經電子化的實作。
壹、數位化文獻與多價文獻模式的基本概念
今天借用加州柏克萊藍效農先生(Howie Lan)在中研院「古籍的漢字處理」討論會中,「多價文獻模式」的報告來說明。藍先生以加州大學數位圖書館(digital library)計劃的經驗說明:從文化史上來看,早期文化的媒介是泥版(如:楔形文字)、甲骨文、竹簡等等,而後是紙本的形式。現在對於新的數位化媒體,應該具備什麼樣的認識?哪些人需要具備?我想上至決策者、專案管理者,乃至最基層的技術執行者,對於數位化文獻都需要具有多價(Multivalent)的認識。
印刷文獻與數位文獻的不同特性是:前者是單塊式(Monolithic),後者是多價式。傳統的文獻觀念,與「書」同義。書是獨立式、互不連結,查詢費時,互參也麻煩,只提供給人「讀」的功能。
「多價」(多訊息層次)文獻模式的定義是:having many values(多種價值), meanings(多種意義), or appeals(多種運用)。此外,還可以類比於原子價位(value)的連結,而成為分子的觀念。由於相同或不同原子的價位連結與互補,才能形成各類各樣的分子結構與多采多姿的物質世界。
「多價」(多訊息層次)文獻模式可分為「層次」(Layers)與「動作」(Behaviors)兩部分。同一個形式的情報層,稱為「層次」。在層次裏可做種種的功能處理,即是「動作」(Behaviors)。層次的例子如:
1. Scanned text image Layer(掃描原版圖檔層次)
2. Encoded text data Layer(編碼版層次)
3. Font reconstructed Layer(字庫再現版層次)
4. Character geometric Layer
5. Metadata Layer
6. Future content Layer
在相同層次(Within-layer)中的動作,例如,在「掃描原版圖檔層次」中,可做下列的動作:
1. Local enlargement(放大)
2. Copy image part(拷貝)
3. Paste image part(貼上)
在「編碼版層次」中,可做下列的動作:
1. Character finding(字元搜尋)
2. String sorting(字串排序)
3. Character counting(字元統計)
在「字庫再現版層次」中,可做下列的動作:
1. Show Character with font(顯示字型)
2. Set Typeface(設定樣式)
3. Horizontal text display(橫排)
4. Vertical text display(直排)
在不同層次間,可做種種功能性的動作:

1. Synonym lens(同義字透鏡):例如:漢簡《老子》的「掃描圖像檔層」,與「字庫再現版層」結
合時,可以得知古今同義字。(見右圖)
2. Translation(翻譯)
數位文獻會產生多價值的功能,最主要是其基本單位不僅是一個字,可以到達一個筆劃,乃至於一個像素(pixel),所以重組(rearranged)和連結(connected)非常簡易快速,不只是給人讀,機器(Processor)也可以配合人來做資訊處理。
因此,假如被傳統的文獻概念所限制,則可能不會想到去連結不同資料(data)的層次。如掃描完後,會覺得這可能只是「死」的影像圖檔("Dead" page images)而已。或者,連結部分資料層次,但僅限於單一的軟體,例如:OCR software's post-process(光學字元辨識軟體的後置作業)。
一、多價文獻模式的特色
整個作業化的文獻運用多價的文獻模式有下列幾個特點:
(一)Incremental Extendable(逐加延伸)
在任何時間、地點、形式、使用者,都可以逐加延伸資料、層次或動作。不像書印出來後,要重新再呈現,還得再版。
(二)Structurally Distribute(結構性分散管理)
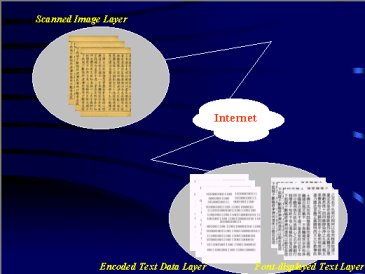
不同層次可以在不同的地方,藉由網際網路(Internet)形成結構性分散管理。以CBETA為例,假設重點放在大正藏第一冊至第五十五冊,採用編碼檔,我們可以和日本SAT合作,由他們做第五十六冊至第一百冊的編碼檔;另外,韓國海印寺可以提供高麗藏的圖檔;京都大學、東京大學有一些手抄的古本可提供圖檔;北京大學有房山石經的圖檔。雖然在不同地方各自管理不同的資料庫,但可以形成一個完整的結構。(見右圖)如《華嚴經》所說的,因陀羅網的世界,即重重無盡的世界。
(三)Internally Complementary(相輔相成)
個別的層次無法完美,但是不同的層次間可以形成互補。例如,由「掃描層」與「字庫再現層」,可以看出古今字的差異。不同版本的圖檔,在同一段落裏顯示出互補性的呈現。
二、數位化文獻與標準化標記語言
為了文獻間能彼此交換,數位化文獻需要標準化的標記語言。如:1986年SGML(Standard Generalized Markup Language,標準通用標記語言),其所用的標籤(tag)可以擴張、檢查;後來為了World Wide Web(全球資訊網)的需求,HTML(HyperText Markup Language,超文件標記語言)是SGML的一項運用,具有指定連結、指定格式的功能。1998年,為了Web最佳運用,開始從SGML推演成XML(Extensible Markup Language,可擴展性標記語言),它可以與HTML整合,並處理資料的顯示, 於SGML中,去除在Web上傳遞資料所不需要的部分(換言之,XML是SGML的子集合)。XML是與SGML互補,可以對Web上的資料作結構化與描述用,而且也可廣泛支援不同種類的應用程式。
如CBETA進行大藏經數位化時的標記處理,以維習安博士的報告為例。對於大藏經本文,先做一個半自動化的標記處理,加上一些標籤(tag);然後再分層處理《大正藏》的腳註(footnotes)。舉例,《華嚴經》有經名、譯者,做標記文字時,第一個層次呈現如圖所示:

腳註的內容:宋元明三個版本有「沙門」,宮內省版本有「法師」等訊息,於下一步驟再加上。

貳、CBETA作業技術介紹
實際上CBETA進行大藏經數位化時,有下列幾項技術性的運用:
一、掃描辨識
在掃描(SCAN)、辨識(OCR)方面,大家都知道掃描大藏經時有一個困難,就是用掃描來辨識雙行字。丹青針對CBETA的需求設計了一個處理大藏經雙行字辨識的OCR軟體。這是我們在處理大藏經中,第一個覺得值得與大家說明介紹的。
二、看圖比對
當輸入或掃描後的電子檔要做校對時,如何去確認哪一個字是正確?一般用人工方式回查原書校對,但比較費時且易有錯誤。例如:到底是「己」還是「已」?這兩個字很相似,若用人工校對的方式,很容易就漏掉了。如果把圖像檔與文字檔連結比對,機器就不會受人為因素干擾,可達高效率、高品質成果的目標。
三、學術研發
CBETA下有設一個研發組,主要負責標記處理和學術研發。德國的維習安博士,對於台灣做電子化時,提供很多做標準化及國際化交換的建議,以及前瞻性的看法。例如:介紹TEI(Text Encoding Initiative, http://www.uic.edu/orgs/tei/)的Guidelines for Electronic Tex Encoding and Interchange。CBETA今年也參加上個月於美國維吉尼亞大學舉行TEI(Text Encoding Initiative)會議。
四、編訂工作手冊
另外,我們還編訂SGML、XML的工作手冊,將標準化的流程記載下來,讓以後進行數位化工作的人,可以節省重新摸索的時間,並記載實際處理的範例。
五、缺字處理
目前缺字處理的方式很多,如國內有「漢字庫」,日本也有一個名為「文字鏡」的漢字庫,目前約有九萬多個漢字可以免費提供使用,約有三百多位學者加入會員。我們目前是用M碼(註1)的方式來處理缺字。
本會組織下還有網路組、發行組。會場外有展示中華電子佛典協會製作的大正藏光碟成品,大家也可以上網使用。我的介紹到此,謝謝。
【附註】
註1:根據杜正民於<以CBETA為例 談大量文獻之建立--漢文藏經電子化作業簡說>(《中央研究院
計算中心通訊》,15卷13期,1999年6月21日,頁122)一文之註四,說明所謂「M碼」就是以M開
頭後面接著一串數字的缺字表示法,是國際上廣為採用的缺字表達法之一。如CBETA以M01079代
表[仁-二+動],即表缺字「鋛」。
【MVD參考資料】
1. Howie Lan (藍效農), "Applications of A New Document Model for Digitalization of East
Asian Classical Documents", Instructional Technology Program Uninversity of
California, Berkeley.
2. Digital Library Project: University of California at Berkeley,
http://elib.cs.berkeley.edu/
3. Thomas A. Phelps, "Multivalent Documents : Anytime, Anywhere, Any Type, Every Way
User-Improvable Digital Documents and Systems", A dissertation for Ph. D,
University of California, Berkeley (1998).
[回gaya首頁]
[佛教圖書館館訊]
[館訊18/19期目次]